ถ้าจำครั้งที่ผมเขียนถึงการทำงานที่ Ookbee Mall และพยายามทำ AWS Cloud ให้มัน Auto-Scaling ได้เนียนๆ ผมรู้สึกเสียดายทันทีที่ไม่รู้จักวิธีการของ The Twelve Factors ในตอนนั้น, ซึ่งถ้ารู้ ก็จะเป็นไกด์อย่างดีที่จะพาผมไปพบ Solution ในการทำเว็บให้รองรับ Cloud และรองรับการขยายของ Cloud ได้ โดยไม่ต้องงมเข็มในมหาสมุทร
ผมมีโอกาสได้ฟังอาจารย์อู๋เล่าเรื่อง The Twelve Factors อยู่หลายครั้ง แต่เพิ่งมีโอกาสได้หาข้อมูลเพิ่มและคุยเพื่อประติดประต่อเรื่องนี้แบบจริงจัง เพื่อให้เห็นความเชื่อมโยงกันเป็นภาพเดียวกัน ผสมกับความรู้อื่นๆและประสบการณ์ตัวเอง เลยลองแชร์ให้ได้อ่านกัน
The Twelve Factors คืออะไร
มันถูกคิดขึ้นมาโดยบริษัท Heroku ผู้ให้บริการ Cloud แห่งแรกของโลก เพื่อชี้ทางสว่างให้แก่เราว่าจะทำ Application Software เพื่อให้บริการผ่านอินเทอร์เนต (SaaS – Software-As-A-Service) อย่างไร และ/หรือ ทำงานร่วมกับ Cloud อย่างไร ให้มีประสิทธิภาพ
ก่อนไปต่อ ขอว่าด้วยเรื่องคุณสมบัติพื้นฐานของ Cloud ก่อน
- Rapid Elasticity – ต้องมีความยืดหยุ่น สามารถเพิ่ม/ลด (Scaling) ทรัพยากรได้ตามความต้องการของผู้ใช้งาน
- On Demand Self Service – ต้องปรับเปลี่ยนการใช้งานได้ตลอดเวลา เช่น ถอด storage เข้า/ออก ในช่วงเวลาใดก็ได้
- Measured Service – ต้องสามารถวัดประมาณการใช้ทรัพยากรณ์และค่าใช้จ่ายได้ตามจริง (Pay as you go)
เมื่อเติมความสามารถของ The Twelve Factors เข้าไป
- จะช่วยลดความแตกต่างระหว่าง Production Environment และ Non-Production Environment (เช่น Development, SIT, UAT, Staging) เพื่อให้สามารถเกิด Continue Integration ได้คล่องตัวที่สุด
- จะช่วยให้ Software ของเรา พร้อมที่จะไปทำ Automation ต่างๆ ต่อไป
- จะสามารถขยายทรัพยากร (Scale up/Scale out) ได้ โดยไม่ต้องเปลี่ยนแปลงสิ่งเดิม เช่น เครื่องมือ (tooling), สถาปัตยกรรม (architecture), หรือกระบวนการพัฒนาซอฟต์แวร์ (development practices)
ซึ่งใน The Twelve Factors ตามชื่อคือมีปัจจัยอยู่ 12 ข้อ แต่พอจะแบ่งเป็นกลุ่มได้ 3 กลุ่ม คือ
- Build – การจัดการ Source Code จนได้เป็น Software เพื่อให้พร้อมใช้งานบน Environment ต่างๆ
- Codebase
- Dependency
- Config
- Backing services
- Build / Release / Run
- Scalable – การรองรับขยายความสามารถของทรัพยากร หรือ Environment เพื่อให้รองรับปริมาณของผู้ใช้งานตามจริง
- Processes
- Port binding
- Concurrency
- Disposability
- Maintainable – การดูแลรักษา
- Dev/prod parity
- Logs
- Admin Processes
ว่าด้วยเรื่อง Build – เปลี่ยน Source Code ให้ได้เป็น Software
1. Codebase – One codebase tracked in revision control, many deploys
Source Code ที่ดี ควรมีที่เก็บเพียงที่เดียว เพื่อลดความสับสนว่าโค้ดล่าสุดอยู่ที่ไหน กับใคร ถ้าดีหน่อยก็คือ ควรมีบันทึกว่าใครทำอะไรกับโค้ดไว้ล่าสุด อะไรบ้าง เมื่อไร หรือคือการนำ การจัดการซอร์สโค้ด (Source Code Management) เข้ามาปฏบิติตาม และหากพูดถึงเครื่องมือสมัยนี้ ก็คงเป็นพวก Version Control ต่างๆ เช่น Git, SVN
แต่ทั้งนี้ Source Code ที่เราเก็บไว้ จะต้องเป็นโค้ดที่พร้อม Build และ Deploy สู่ Environment ต่างๆเสมอ ไม่ว่าจะ Development Server หรือแม้กระทั่ง Production Server ก็ตาม ข้อนี้ข้อเดียวก็ท้าทายมากๆ เพราะต้องใช้การจัดการทางด้าน Busines และ Technical หลาย Practices พอสมควร เช่น
- ต้องมีกระบวนการรวบรวมโค้ดกันบ่อยๆ (Continuous Integration) เพื่อเก็บเข้าสู่ระบบหรือ Version Control
- ต้องผ่านกระบวนการทดสอบอย่างครอบคลุมสมบูรณ์ (Comprehensive Test) มาเรียบร้อยแล้ว
- ต้องมีการจัดการ Package, Library และสิ่งต่างๆที่เกี่ยวข้องกับโค้ดของเรา เพื่อทำการติดตั้งใหม่ได้ทุกครั้งที่ Deploy (Dependency Management) – จะขยายความในข้อ 2. Dependency
- ต้องมีการจัดการ Config เพื่อให้สามารถใช้กับ Environment ต่างๆ ได้ โดยไม่ต้องทำการ Build ใหม่ (Configuration Management) – จะขยายความในข้อ 3. Config
- จากข้อ 1 – 4 ทุกอย่างต้องเป็น Automation เพื่อที่ทุกครั้งมีการแก้ไขเปลี่ยนแปลงโค้ด ก็สามารถพร้อม Deploy ได้เสมอ (Automated Build and Automated Test) – จะขยายความในข้อ 5. Build/Release/Run
ความท้าทาย คือ 5 ข้อที่กล่าวมาทั้งหมด พร้อมแล้วหรือยัง, และเรื่องการใช้ Version Control อย่างเช่น Git เราออกแบบการกระบวนการทำงานอย่างไร (Branch Strategy)
 รูปจาก https://www.slideshare.net/saffyre9/responsive-web-design-14770110/14-Single_Code_Base_Dawn_Wentzell
รูปจาก https://www.slideshare.net/saffyre9/responsive-web-design-14770110/14-Single_Code_Base_Dawn_Wentzell
2. Dependency – Explicitly declare and isolate dependencies
เมื่อเรามี Source Code ที่พร้อมจะใช้งานแล้ว อย่าลืมว่าโค้ดจะไม่สามารถทำงานได้ด้วยตัวเอง ดังนั้นจะมีส่วนที่เกี่ยวข้องสองอย่างคือ
- Application Dependency – โค้ดเรามี Package, Library อะไรที่ต้องใช้งานบ้าง เช่น CURL, ImageMagick, JSON, ฯลฯ
- Middleware Dependency – โค้ดเราต้องถูกทำงานผ่านซอฟต์แวร์ต่างๆ เช่น Web Server ฯลฯ
ดังนั้นเราจะต้องกำหนดซอฟต์แวร์ Dependency รวมไปถึง Version ที่จะถูกใช้งาน (ในแต่ละ Environement) อย่างถูกต้องด้วย
และที่สำคัญ ทุกครั้งที่มีการแก้ไขเปลี่ยนแปลง Source Code และมีการ Build ใหม่ ก็จะต้องทำการเรียกใช้หรือติดตั้ง Dependency ใหม่เสมอ ดังนั้นถ้ากระบวนการเหล่านี้เป็น Automation ก็แทบจะหลีกเลี่ยงไม่ได้เลยที่จะต้องใช้เครื่องมือประเภท Package/Dependency Management เช่น Composer, Nuget, CPAN, Rubygems
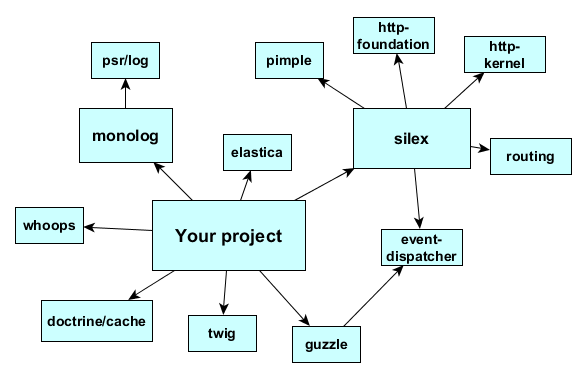 รูปจาก http://slides.com/espenhovlandsdal/dependency-management-with-composer/fullscreen
รูปจาก http://slides.com/espenhovlandsdal/dependency-management-with-composer/fullscreen
3. Config – Store config in the environment
เมื่อ Source Code ที่ผ่านการทดสอบอย่างสมบูรณ์และ Build พร้อมจะ Deploy ไปทุกๆที่ แปลว่า เราจะต้องมีการจัดการเรื่องของ Config ไว้เรียบร้อยแล้ว
ซึ่งในความหมายของ Config ที่ว่ามานี้ เช่น
- การจัดการข้อมูลที่ระบุถึง Resource ต่างๆ อย่าง Database, Memcached, ฯลฯ
- การจัดการรหัสผ่านหรือ Credentials ที่จะติดต่อไปยัง external services ต่างๆ เช่น Amazon S3, Facebook, Twitter, ฯลฯ
- การจัดการที่เกี่ยวกับข้อมูลของ Environment เอง เช่น Hostname, IP ฯลฯ
ความท้าทายคือ ทำอย่างไร เมื่อเวลา Deploy ไปสู่ Environment ต่างๆ แล้วไม่ต้องมาแก้ Config ใหม่ทุกครั้ง เพื่อลดข้อผิดพลาด เช่น ขึ้นเครื่อง Develop เสร็จ ก็ไม่ต้องแก้ Config และ Build ใหม่ เพื่อขึ้น UAT หรือ Production อีกครั้ง
ผมเคยคิดในใจเล่นๆ ว่า “เอ้า ถ้าเช่นนั้นก็ทำ file config เตรียมไว้ แล้วให้โค้ดเรียกใช้ตาม Environment ต่างๆ ก็ได้นี่นา…”
คำตอบคือ วิธีการแบบนี้ไม่สะดวกและไม่ปลอดภัยครับ เพราะคนที่เห็น Source Code เราทุกคน ก็จะเห็นรหัสผ่านเราทั้งหมด, หรือบางบริษัทมีนโยบายเปลี่ยนรหัสผ่านทุก 3 เดือน แปลว่าอนาคตก็ต้องมาแก้ Config, ทำการทดสอบระบบทั้งหมดใหม่ (Regression Test), ทำการ Build ใหม่ และ Deploy ใหม่ กระนั้นเชียวหรือ.. (ปล. อย่าฝืนทำเป็นไฟล์ และไปตั้งให้ใครสักคนมาดูแลไฟล์ Config นะ, มันบาป)
ซึ่งใน The Twelve Factors ได้บอกชัดๆเลยว่า ให้นำ Config ไปใส่ไว้ใน Environment ซะ เพราะทำการแก้ไขได้ง่าย ไม่ต้องแก้โค้ด, คนเขียนโค้ดไม่สามารถมองเห็นข้อมูลได้ (ถ้าไม่เข้าไปดูใน Server), ฝังอยู่ในแต่ละ Environment ของใครของมัน
ที่กล่าวมาทั้งหมด เรารู้จักมันในนามของ Environment Variable นั่นเอง
ความท้าทาย คือ เราจะจัดการ Environment Variable ทุกตัว ของทุกระบบที่เรามีได้อย่างไร เพื่อไม่ให้สับสน ชื่อซ้ำ เข้าใจได้ง่าย และปลอดภัย
4. Backing services – Treat backing services as attached resources
ความหมายคือ Service ต่างๆ ที่ถูกใช้ใน Application Software ของเรา โดยเรียกใช้ผ่าน Network เช่น
- Database (อย่าง MySQL, MSSQL)
- Messaging/Queueing Systems (อย่าง RabbitMQ)
- SMTP services เพื่อใช้งาน email (อย่าง Postfix)
- Caching Systems (อย่าง Redis, Memcached)
ซึ่ง Service เหล่านี้ควรจะต้องแยกออกจาก Application ของเรา และสามารถนำเข้าใช้งาน หรือถอดออกจกาการใช้งาน เพื่อเปลี่ยนใหม่ได้โดยง่าย และไม่ต้องไปแก้ไข Source Code ใหม่ (โดยใช้หลักการแก้ไข Config ตามข้อ 2)
ดังนั้นจะสังเกตได้ว่า Cloud Service ต่างๆ ทำไมต้องมีบริการพวก Database, Caching, Messaging, Caching, ฯลฯ มาให้เราเสียเงินมากมาย ก็เพราะการนี้นี่เอง
ความท้าทาย คือ การแยก External Service เหล่านี้ออกจากระบบเดิม และทำการ Migration เพื่อไม่ให้กระทบระบบทั้งหมด รวมถึงการจัดการ Service เหล่านี้ให้ไม่เกิดปัญหาคอขวด หากต้องใช้ร่วมกันหลายๆระบบ พร้อมกัน รวมถึงการทำสำรองข้อมูลต่างๆ และการดูแลตรวจสอบกรณีเกิดปัญหาทงาด้าน Network ที่ใช้รับส่งข้อมูล
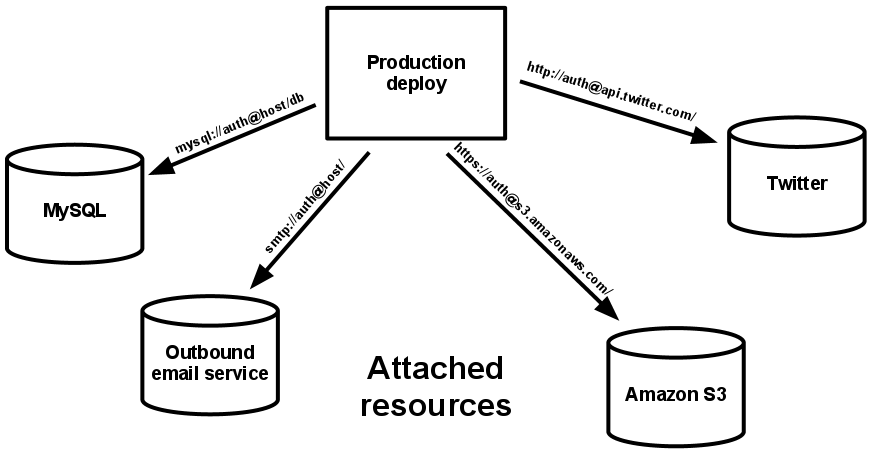 ภาพจาก https://12factor.net/backing-services
ภาพจาก https://12factor.net/backing-services
5. Build / Release / Run – Strictly separate build and run stages
เมื่อ Source Code พร้อมที่จะ Deploy แล้ว เราก็จะทำ 3 ขั้นตอน โดยแบ่งเป็น
- Build stage – คือ แปลงจาก Source Code ไปเป็นซอฟต์แวร์ที่พร้อมจะทำงาน (executable)
- Release stage – คือ นำซอฟต์แวร์ที่ได้จากขั้นตอน Build มารวมกับ Config เพื่อเตรียมนำไปใช้งาน
- Run stage (หรือ “runtime”) – นำซอฟต์แวร์ไปใช้งานใน Environment ต่างๆ
ความท้าทาย คือ The Twelve Factors บอกว่า การกระทำทั้ง 3 ขั้นตอนนี้ จะต้องแยกออกจากกันชัดเจน ด้วยเหตุผลที่ว่า ถ้าขั้นตอนในการทำ Release มีปัญหา อย่างน้อยก็ไม่ต้อง Build ใหม่, หรือถ้า Run Stage มีปัญหา ก็แค่ทำคำสั่ง Run ใหม่อีกครั้ง ไม่ต้อง Build/Release ซ้ำอีกรอบ
ดังนั้น การ Build/Release หมายถึงไม่ได้ไปข้างหน้าอย่างเดียว แต่จะต้องถอยกลับได้ด้วย (Rollback) นะ ถ้ามันพังในขั้นตอนใดขั้นตอนหนึ่ง ซึ่งการจะ เดินหน้าหรือถอยหลังได้ จะต้องถูกกำหนดด้วย Release ID ที่ไม่ซ้ำกัน ขึ้นมา เพื่อบ่งบอกว่าถูก Build/Release เมื่อไหร่ จึงเป็นที่มาว่า เราจะต้องกำหนดเลข Build Version และเลข Release Version ของซอฟต์แวร์ไว้ด้วย
เมื่อมาถึงจุดนี้ เลี่ยงไม่ได้เลยที่จะต้องทำ Software versioning และมีที่เก็บซอฟต์แวร์เวอร์ชั่นต่างๆ ไว้ หรือที่เราเรียกว่า Artifacts Repository หรือ Binary Repository
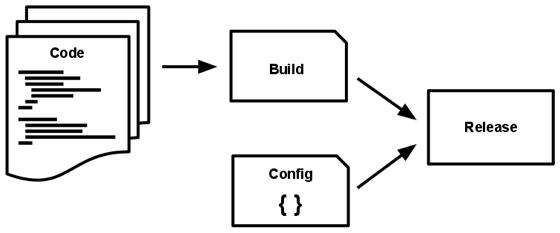 รูปจาก https://12factor.net/build-release-run
รูปจาก https://12factor.net/build-release-run
สรุปขั้นตอนในการ Build
ถ้าทำทั้งหมด 5 ข้อ ที่ว่ามานี้ เราจะได้ Source Code และ Environment ที่พร้อมทำการ Build / Release / Run ซึ่งถ้าคิดดีๆ มันคือ กระบวนการ Continue Integration และ Continue Deployment นั่นเอง และสิ่งที่จะทำให้สมบูรณ์ยิ่งขึ้น คงเลี่ยงไม่ได้ที่จะต้องทำทั้งหมดเป็น Automation ด้วย
ว่าด้วยเรื่อง Scalable – เพื่อรองรับปริมาณของผู้ใช้งานตามจริง
6. Processes – Execute the app as one or more stateless processes
ข้อนี้ เป็นหัวใจหลักอย่างหนึ่งในการทำ Application Software ให้รองรับการทำงานพร้อมกันในหลายๆ Server และถ้าเป็นคนไม่เคยทำมาก่อน อาจจะคิดไม่ถึงเลยทีเดียว เพราะปัญหาคือ ทุกครั้งที่ Application เราทำงาน มันจะมีการสร้าง Session ขึ้นมา (หรือกรณีที่เราเขียนโค้ดเพื่อตั้งใจให้ใช้ Session) ดังนั้น เมื่อ Cloud Server มีหลายตัว แต่ Session ถูกสร้างไว้แค่บนเครื่องใดเครื่องหนึ่ง คราวนี้งานเข้าแน่นอน เพราะถ้าผู้ใช้งานเปิดเว็บเราอีกครั้ง แปลว่าอาจถูกเรียก Cloud Server อีกตัวหนึ่งก็ได้ แล้วผู้ใช้คนนั่นก็จะไม่พบ Session เดิม เช่น ระบบ Member Login เป็นต้น
หรือการทำงานที่มี Process ตั้งแต่ 2 ตัวขึ้นไป เช่น สั่งให้ Process A ทำงานเสร็จ แล้วส่งไปต่อให้ Process B ทำงานต่อ แบบนี้เมื่อ Cloud Server ไม่ได้ถูกทำงานบนเครื่องเดียวกัน มันจะไม่สามารถทำงานต่อกันได้อย่างสมบูรณ์
ซึ่งใน The Twelve Factors จึงบอกว่า ให้ Application ของเราทำงานเป็นแบบ Stateless Process ซะ
หมายความว่า Application ของเราจะไม่มีการเก็บข้อมูลบน Cloud Server ของตัวมันเอง เมื่อมันถูกสั่งให้ทำงาน, แต่หากจำเป็นต้องใช้ล่ะ เราจะต้องทำ Backing Services ขึ้นมาเก็บข้อมูลเหล่านั้นแทน เช่น การตั้ง Server กลาง อย่าง Redis, Memcached เพื่อเก็บ Session ที่ใช้ร่วมกันของทุกๆ Cloud Server
เมื่อก่อนที่ผมใช้ Amazon Cloud มันมีฟีเจอร์หนึ่งคือ “sticky sessions” พอคลิกเปิดใช้งานปุ๊บ มันจะทำการย้าย session ของเราทั้งหมดไปไว้ใน memory ที่หนึ่ง ซึ่งถ้าผู้ใช้คนเดิมเข้ามา เขาก็จะสามารถใช้ได้ต่อเนื่องโดยไม่เกิดปัญหาใดๆ ง่ายและสะดวกมาก แต่ The Twelve Factors บอกว่า ไม่ควรใช้ เพราะ Session data ที่ดี ควรมีเวลาหมดอายุด้วย ไม่ใช่ถูกจำไว้ตลอดจนกว่าผู้ดูแลระบบจะลบออกเอง ตัวอย่างที่ง่ายสุดว่าทำไมไม่ควรจดจำไว้ตลอดเวลาแบบเดิม เช่น การทำ Tokenize Session ในระบบ Member Login เป็นต้น อย่างน้อยต้องมีระยะเวลาหนึ่งที่ผู้ใช้ต้องกลับมา Login ใหม่อีกครั้ง เพื่อความปลอดภัย
ความท้าทาย คือ ถ้า Backing Services ที่เก็บ Process พวกนี้ตาย ก็พินาศกันหมดแน่นอน ดังนั้นต้องวางแผนให้ดี ในการรับโหลดที่มากขึ้น จากทุกๆระบบ (อ่านเพิ่มเติมใน ข้อ 8. Concurrency)
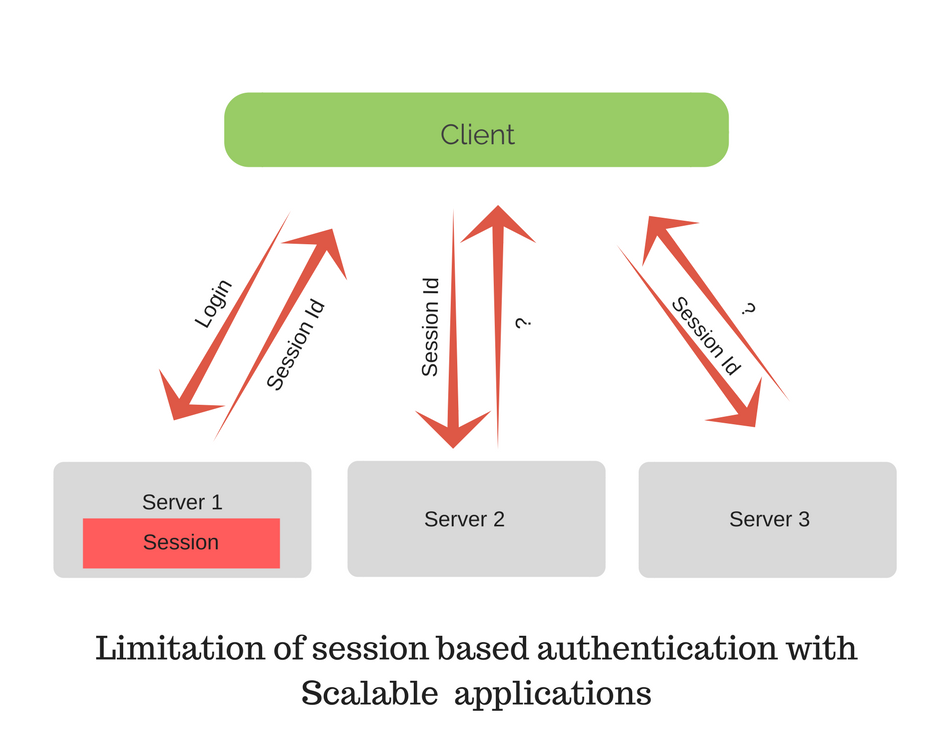 ภาพจาก http://www.indexnine.com/blog/
ภาพจาก http://www.indexnine.com/blog/
7. Port binding – Export services via port binding
เมื่อ Application ของเรามีการเรียกใช้งาน Backing Services หรือ Application เราเองเป็น Backing Services ให้กับ Application อื่นๆ จะเกิดการคุยกันผ่าน HTTP ดังนั้น เมื่อ Cloud Server ของเรา มีความยืดหยุ่น ถูกเพิ่ม/ลด ตลอดเวลา ทุกครั้งที่มีการเพิ่ม เราไม่สามารถระบุที่อยุ่ปลายทางชัดเจนได้ อย่างเช่น IP Address
ดังนั้น ใน The Twelve Factors จึงแนะนำว่า ให้ระบุเลยว่า Service เราแต่ละตัวใช้ Port อะไร จากนั้นเวลาเรียกใช้ ก็ไม่ต้องไปสนใจมันว่าอยู่ที่ IP Address ไหน รู้แค่ว่า ถ้าอยู่วง Network เดียวกัน แต่ต่อด้วย Port นี้ จะต้องได้ Service นี้เสมอ
เช่น http://localhost:5000/ เรียกหน้าเว็บ, แต่พอเรียกใช้ API จะต้องเข้าที่ http://localhost:5001/, หรือใช้ MySQL จะเรียกที่ http://localhost:3306/ เป็นต้น
ความท้าทาย คือ นโยบาย Security ของเราเอง จากที่ประสบพบเจอมา บริษัทเกือบทุกที่มีการกำหนดให้ใช้งานได้เฉพาะบาง Port เราอาจต้อง Define กันให้ชัดแต่แรกว่าจะใช้ Port ใดในระบบไหนบ้าง และต้องอนุญาตขอเปิดใช้ตามนั้น และวางแผนป้องกันในเรื่องการเข้าถึงของแต่ละระบบด้วย
8. Concurrency – Scale out via the process model
เมื่อเราทำเป็น Stateless Process โดยแยกออกมาเป็น Backing Services ดังนั้นมันจึงเป็นอิสระจากกัน เราจึงขยายทรัพยากร (Scale out) ให้กับมันได้โดยไม่ส่งผลกระทบกับการทำงานทั้งหมดของระบบ หรือไม่จำเป็นต้องขยายทรัพยากรในส่วนอื่นๆที่ไม่เกี่ยวข้องด้วย
ซึ่งในหลักการข้อที่ 6. Process และ 8. Concurrency นี้ เป็นแนวคิดแบบเดียวกับ Microservices ที่แยกการทำงานออกเป็นส่วนๆ เมื่อตัวไหนใช้ทรัพยากรมาก ก็ทำการ Scale out เพิ่มออกไปให้รองรับได้กว้างขึ้น
ความท้าทาย คือ หากผมสมมติว่า Application ของเรารองรับการ Scale out ได้แล้ว คำถามต่อมาคือ ระบบ Infrastructure ที่เราใช้ในปัจจุบัน รองรับแล้วหรือไม่ หรือยังเป็นการปิดเครื่อง Server เพิ่ม Memory เพิ่ม Harddisk อยู่แบบเดิม?
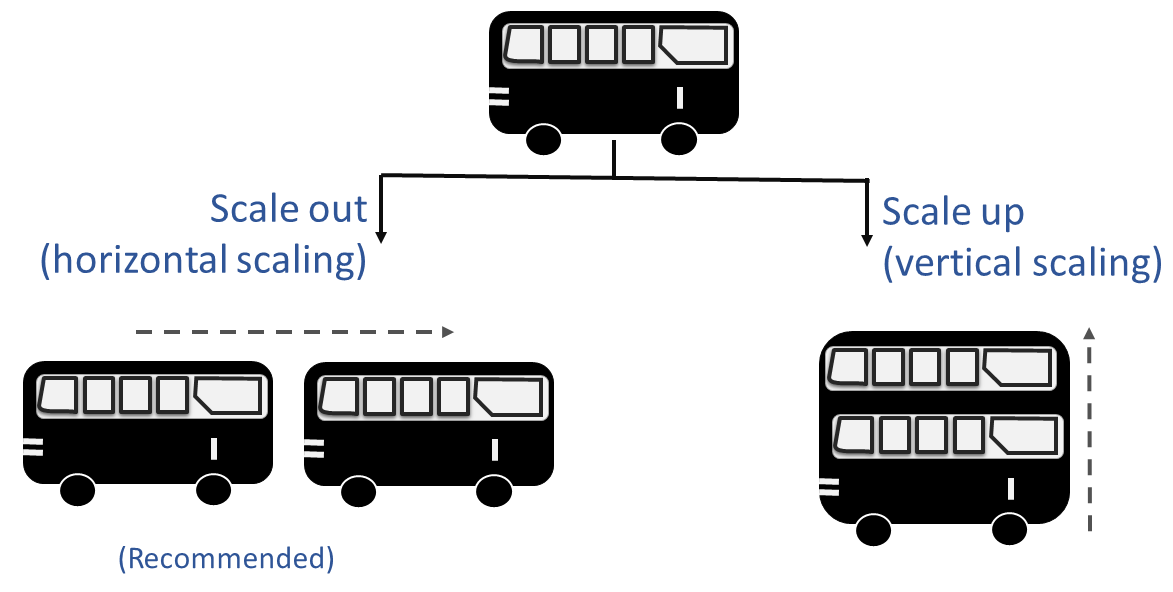 รูปจาก https://docs.bmc.com/docs/TSLogAnalytics/110/sizing-and-scalability-considerations-721194160.html
รูปจาก https://docs.bmc.com/docs/TSLogAnalytics/110/sizing-and-scalability-considerations-721194160.html
9. Disposability – Maximize robustness with fast startup and graceful shutdown
ในข้อนี้บอกว่า Application ของเราจะต้องมีการเริ่มต้นทำงานได้ไว (fast startup) และจบการทำงานได้อย่างสมบูรณ์แบบ (graceful shutdown) หมายความว่า Process ต่างๆ จะต้องถูกจัดการได้อย่างดี ตั้งแต่เริ่มต้นจนจบ
ข้อนี้ให้นึกถึง Microsoft Windows ที่เมื่อก่อนสมัยใช้ Windows 95,98,Me กว่าจะเปิดเครื่องใช้งานได้ เรานั่งมองโลโก้ Windows อยู่พักใหญ่ๆ เพราะมันโหลดทุกสิ่งทุกอย่างขึ้นมาเพื่อพร้อมทำงาน กลับกัน Windows รุ่นใหม่ๆ อย่าง 7,8,10 ที่เปิดขึ้นมาแล้ว ใช้เวลาไม่ถึง 1 นาที ไวอย่างเห็นได้ชัด
และเช่นกัน ในตอนที่เรากด Shutdown Windows เพื่อปิดการทำงาน ยิ่งเราเปิดโปรแกรมใหญ่ขนาดไหน หรือเยอะมากแค่ไหน มันก็จะใช้เวลาปิดนานขึ้น เพราะ Windows กำลังทำการ Shutdown Process อย่างสมบูรณ์แบบ เพื่อให้แน่ใจว่าทุกการทำงาน ทำงานจบครบถ้วน ไม่มีงานค้าง เช่น การบันทึกเอกสาร ก็จะต้องบันทึกให้เสร็จ ไม่ใช่ว่าผู้ใช้สั่งปิดปุ๊บ ก็ปิดทันที ทั้งที่ Process การบันทึกไฟล์ยังทำงานไม่จบ ผลคือ เอกสารเราก็จะเสียหายได้ นี่แหละที่เรียกว่า graceful shutdown
ในตัวอย่างงานจริง สมมติลูกค้ากำลังทำรายการโอนเงินจากบัญชีตนเองไปยังบัญชีปลายทาง แปลว่า Process นั้นจะต้อง บันทึกลดเงินเรา และทำการบันทึกเพิ่มเงินที่บัญชีปลายทาง และถ้าหากเวลานั้นลูกค้าใช้น้อย Cloud Server เราทำงานอัตโนมัติ ถูกสั่งให้ลดจำนวน Server ลง แล้วบังเอิญว่าตัวที่ถูกปิดเป็นตัวที่กำลังทำ Process บันทึกข้อมูลเพิ่มเงินปลายทาง คราวนี้จะมีปัญหาทันที เพราะ เงินเราหายไป แต่เงินปลายทางไม่เพิ่มขึ้น กรณีคล้ายๆแบบนี้ ผมเคยเจอในเหตุการณ์ทำงานจริงมาแล้ว แม้ระบบของ Cloud Provider จะช่วยเราได้ส่วนหนึ่ง แต่ก็มีโอกาสที่เกิดขึ้นได้
ความท้าทาย คือ พวก Docker, Amazon Cloud ต่างๆ มันรองรับเรื่องนี้แล้ว แต่ Application เราล่ะ ต้องทำอย่างไร และปรับอย่างไร ซึ่งหลายภาษามีรองรับส่วนนี้อยู่แล้ว
สรุปขั้นตอนในการ Scalable
จะสังเกตได้ว่า พอพูดถึง Scalable เมื่อก่อนเราจะนึกถึง Infrastructure แต่เนื้อหาทั้งหมดที่กล่าวมาเกือบทุกข้อ (ยกเว้น Port Biding) ต้องแก้ไข Application เราให้รองรับ ซึ่งข้อนี้ผมเคยพลาดมาแล้วตอนพยายามใช้ Amazon Cloud ในการทำ Auto-Scaling สุดท้าย มาพบว่า ต้องทำ Process ให้เป็น Stateless รวมถึงการอัพโหลดไฟล์หรือใช้ไฟล์ร่วมกันต้องมี File Object Storage เป็น Backing Services เข้ามาร่วมด้วย ประมาณนี้
ว่าด้วยเรื่อง Maintainable – การดูแลรักษา
10. Dev/Prod Parity – Keep development, staging, and production as similar as possible
เป็นข้อที่อธิบายถึงการทำ Environment ให้มีความแตกต่างกันน้อยที่สุด เช่น Development/SIT/UAT กับ Production ใช้ซอร์ฟแวร์และเวอร์ชั่นเดียวกันทุกตัว มี Config ใกล้เคียงกันทุกอย่าง เป็นต้น รวมถึงการทำ Deployment จาก Environment หนึ่งไปยังอีก Environment หนึ่ง จะต้องทำได้ไว
ซึ่งปัญหาเหล่านี้เรียกรวมๆว่า มีช่องว่างของความแตกต่างระหว่างรูปเดิม (Traditional) กับรูปแบบใหม่ที่ The Twelve Factors แนะนำ ซึ่งแบ่งได้เป็น 3 เรื่อง ดังนี้
- เรื่องของเวลา (The time gap): แต่เดิมที่นักพัฒนาต้องใช้เวลาเป็นวัน เป็นสัปดาห์ หรือเป็นเดือน เพื่อนำ Application เข้าสู่ Production ก็จะต้องลดช่องว่างเหล่านี้ ให้เหลือเพียงหลักชั่วโมง หรือนาทีได้
- เรื่องของคนและกระบวนการ (The personnel gap): แต่เดิมนักพัฒนาต้องเขียนโค้ด ส่งให้ทีม Tester ทดสอบ และส่งให้ทีม Infrastructure ทำการ Deploy ซึ่งการส่งกันไปๆมาๆ ก็จะต้องลดช่องว่างเหล่านี้ได้ด้วยการทำ ให้จบเกือบทั้งหมดได้ด้วยนักพัฒนาเท่านั้น
- เรื่องของเครื่องมือ (The tools gap): แต่เดิมนักพัฒนาใช้ Nginx, SQLite, OSX บนเครื่องตัวเอง แต่พอไปขึ้นที่ Production กลายเป็น Apache, MySQL, Linux ก็จะต้องลดช่องว่างเหล่านี้ได้ด้วยการทำให้เครื่องของนักพัฒนาหรือ Development Environment ทั้งหมด มีความเหมือนกับ Production มากที่สุด
ความท้าทาย คือ เราจะต้องจำลองทุก Environment ให้คล้ายกัน ในเชิงรูปแบบ เครื่องมือ กระบวนการ แต่ไม่ใช่ในเชิงปริมาณ (อย่างเช่น บน Production มี Web Server ใช้ Apache 2.4 จำนวน 10 ตัว แต่ในเครื่อง Developer มี Apache 2.4 จำนวน 1 ตัวก็โอเคแล้ว) ซึ่งปัจจุบันมีเครื่องมือให้ใช้มากมายในกลุ่ม Containerization อย่าง Docker รวมถึงการทำให้เกิด Continue Integration และ Continue Deployment เพื่อให้มีการ Deploy ได้อย่างมีประสิทธิภาพและต่อเนื่อง
 รูปจาก https://www.infoq.com/presentations/12-Principles-Deploy-Apps
รูปจาก https://www.infoq.com/presentations/12-Principles-Deploy-Apps
11. Logs – Treat logs as event streams
โดยปกติแล้ว Application เรามักทำการเก็บ Logs ในรูปแบบข้อมูล เช่น เก็บเป็นไฟล์, ลง Database ซึ่งถ้าเกิดเราอยากรู้การทำงานใดๆ ทันที ก็ต้องคอยเข้าไปเปิดชุดข้อมูลเหล่านั้น ยิ่งถ้าออกแบบไม่ดี ก็อ่านยาก ค้นยากไปอีก
ซึ่งใน The Twelve Factors แนะนำว่า ให้ทำการพ่น Logs การกระทำต่างๆ มันออกมาซะ ในรูปแบบของ stdout (Standard Output) จากนั้นค่อยเอาซอร์ฟแวร์เก็บ Logs มา capture และจัดการข้อมูลเหล่านี้อีกที ซึ่งข้อดีคือ พอ Application เราพ่น stdout ปุ๊บ เราจะสามารถเห็น logs การกระทำต่างๆ ได้เลย และถ้าต้องการดูย้อนหลัง ค่อยไปดูจากระบบ Logs อีกครั้ง (ซึ่งระบบพวกนี้เก็บได้ครอบคลุม ทำงานได้ไว และประหยัดเวลากว่าที่เราจะมาทำเอง) ในที่นี้ตัวอย่างของระบบ Logs ที่เป็น Open Source และทำงานได้ตามข้อนี้ เช่น Logplex และ Fluentd
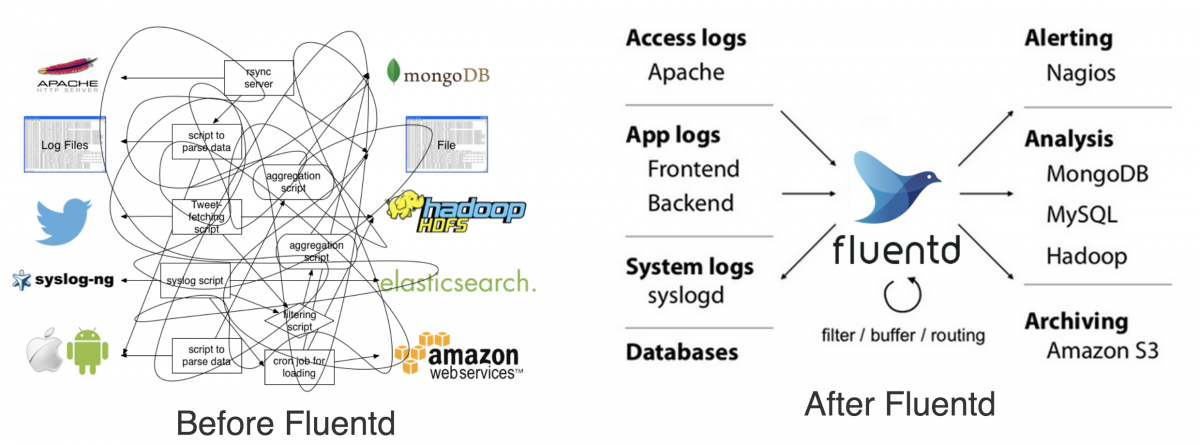 ภาพจาก https://www.fluentd.org/architecture
ภาพจาก https://www.fluentd.org/architecture
12. Admin processes – Run admin/management tasks as one-off processes
หมายถึงการแยกชุดคำสั่งที่ใช้ทำงานระดับ Server Admin อย่างเช่น Database Migrations, หรือ Shell, Command อะไรบางอย่าง ออกจาก Application ของเราซะ
แต่ก็ต้องใช้คำสั่งข้างต้นเหล่านั้น อยู่ในชุดโค้ดเดียวกับ Application ของเรา, เมื่อใช้เสร็จแล้ว จะต้องทำลายทิ้งให้หมด
ยกตัวอย่างเช่น ผมดาวน์โหลดโค้ด WordPress มาติดตั้ง โดยมันจะมีชุดติดตั้งมาให้ ซึ่งกระบวนการติดตั้งนี้จะมีการ Import Database, การสร้างโฟลเดอร์, การ Change Permission File อยู่ในนั้นด้วย (เรียกว่า Admin processes) จากนั้นเมื่อผมติดตั้งเสร็จ ก็ต้องทำทำการลบไฟล์ติดตั้งทิ้งทั้งหมดเพื่อความปลอดภัย
หรืออีกตัวอย่างหนึ่งคือ การใช้ entrypoint ใน Docker เพื่อให้ทำคำสั่ง Shell อะไรบางอย่าง เช่น Import Database, Delete Cache หนึ่งครั้ง จากนั้น Application ถึงเริ่มทำงานได้ โดยที่จะไม่มีใครสั่งคำสั่งนั้นได้อีก (ถ้าไม่เข้ามาถึงใน Shell Server ของเรา)
รวมถึงการปิดการเข้าถึงภายในระบบของ Server ด้วย เพื่อป้องกันการลักไก่เข้ามากระทำการเองนอกเหนือจากที่ทำชุดโค้ดไว้ให้
ความท้าทาย คือ ต้องสร้าง Policy เหล่านี้กับเหล่าทีมที่ดูแล Infrastructure ทั้งหมด รวมถึงบุคคลที่จำเป็นต้องเข้าถึงทั้งหมด ว่าห้ามทำอะไรบ้าง และให้ใช้วิธีการอย่างอื่นทดแทนได้อย่างไรบ้าง
สรุปขั้นตอนในการ Maintainable
ผมมักพบว่ากลุ่มของ Maintainable สามข้อหลังนี้ เป็นสิ่งที่บริษัทหลายที่มักประสบภัยกันมาก โดยเฉพาะเรื่องการทำให้ Environment คล้ายกันทั้ง Developer และ Production จากนั้นพอ Application ขึ้นได้แล้ว ก็มักลืมที่จะทำหรือดู Logs ในส่วนของ Application เพราะส่วนมากดูแต่ Infrastructure ว่า CPU/Memory ฯลฯ ขยับขึ้นลงเป็นอย่างไร สิ่งเหล่านี้เองที่เรามักตกม้าตาย แล้วมาทำตามกันทีหลังเมื่อประสบปัญหาไปแล้ว
สรุปเรื่องราวทั้งหมดของ The Twelve Factor
ผมก็ยังรู้สึกเสียดายเหมือนตอนต้น ว่าทำไมไม่รู้จักกันให้เร็วกว่านี้ จะได้ใช้ Cloud ได้อย่างมีประสิทธิภาพมากขึ้นอีกเยอะ, และถ้าใครอยากจะเริ่มลองทำดู แต่ยังไม่อยากทำทั้งหมด 12 ข้อ ผมแนะนำให้ลองทำตั้งแต่ข้อ 1-6 ดูก่อนก็ได้ แค่นี้ Application ของเรา ก็จะมีประสิทธิภาพมากขึ้นแล้ว ไม่ว่าจะอยู่บน Cloud หรือไม่อยู่ก็ตาม
ถ้าอ่านมาถึงตรงนี้ แล้วอยากทำ ลองไปอ่านต่อได้ที่
อยากทำ THE TWELVE FACTORS จะเริ่มต้นอย่างไรดี และต้องเรียนรู้อะไรบ้าง
—
ข้อมูล อ้างอิง
เว็บน่าสนใจอื่นๆที่พูดถึง The Twelve Factor
- Somkiat.cc – การพัฒนาระบบตามแนวคิด 12 Factor
- 12 Factors App : Methodology for building software-as-a-service (Part 1)
- สร้างเว็บให้มีประสิทธิภาพ ด้วย 12 บัญญัติจาก Twelve Factor App