ผมได้ยินกิตติศัพท์ AWS Lambda มานานมาก แต่ไม่เคยเข้าไปดูจริงจัง รู้แค่มันเป็น Service ที่มีไว้ทำ Process สักอย่าง เมื่อเสร็จแล้วก็ทำลายตัวเองทิ้งไป คิดเงินตามการเรียกใช้และระยะเวลาที่ใช้ทำงานเท่านั้น หรือที่เรียกกันว่า Serverless
ช่วงนี้ได้มีโอกาสเล่นมันแบบจริงๆจังๆ เลยรู้สึกว่า คนต้นคิดเรื่อง Serverless เจ๋งดี เลยอยากมาเขียนสรุปให้อ่านกันสำหรับคนที่ไม่รู้อะไรเลย ผ่านตัวอย่างบริการของ AWS Lambda
Serverless คืออะไร?
Serverless ถ้าแปลตรงตัวก็คงเรียกว่า “ไม่มี Server” กล่าวคือ เมื่อมีการเรียกใช้งานอะไรสักอย่าง มันจะสร้าง Server ชั่วคราวขึ้นมาเพื่อประมวลผล และเมื่อส่งผลลัพธ์ให้เราเสร็จ มันก็จะหยุดทำงาน หรือทำลายตัวเองทิ้งไป
ปล. จริงๆ มันก็มี Server นั่นเอง ผมอยากแปลมันว่า “Server ชั่วคราว” มากกว่า แต่เพื่อความเข้าใจตรงกันขอใช้คำแปลแบบท่านอื่นๆแล้วกัน เพราะส่วนตัวคิดว่า คำว่า “Serverless ทำงานแบบไร้ Server” มันเป็นข้อความทางการตลาด ให้คนสนใจ แต่ค่อนข้างสร้างความสับสนว่าเป็นไปได้ด้วยหรอ?!
iFew
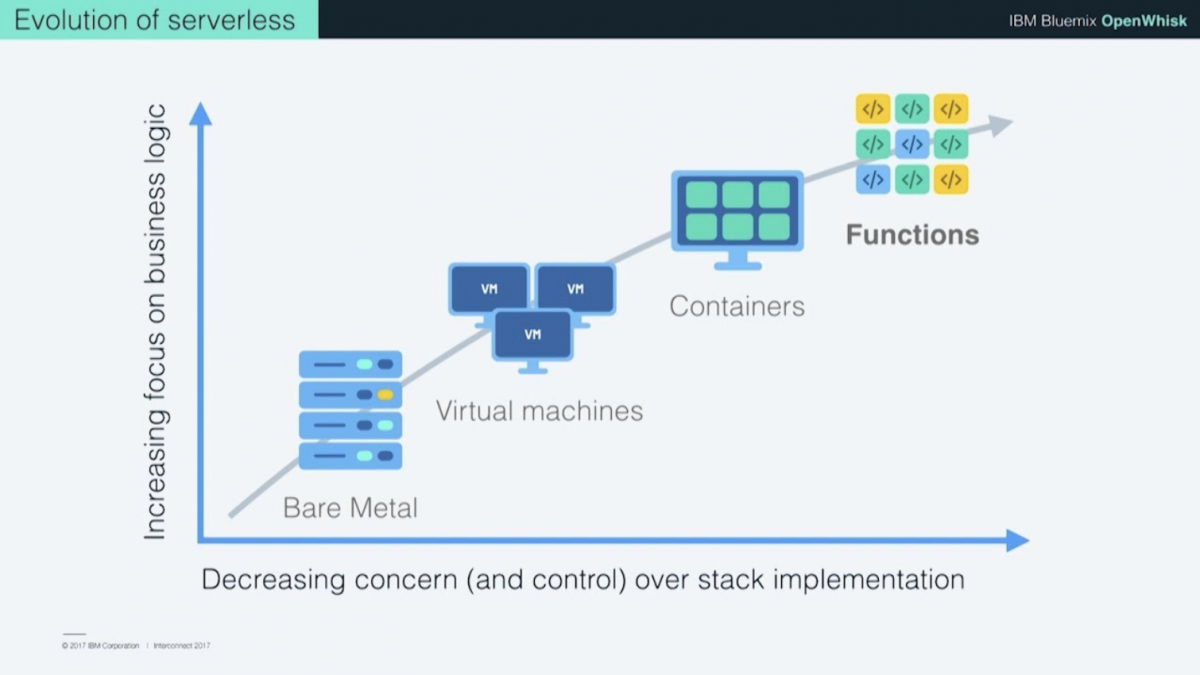
ถ้าไล่ประวัติตามรูปด้านบน เริ่มต้นมาจากสมัย Internet มาแรกๆ ที่เราต้องตั้งเครื่อง Server ทีละตัว หรือหลายๆเครื่องตามปริมาณที่รองรับคนได้ ต้องดูแลเองทุกอย่าง
จนถึงวันหนึ่งที่อุปกรณ์ต่างๆ เริ่มมีราคาถูกลงและสเปกแรงขึ้น เราจึงประหยัดต้นทุนด้วยการจำลอง Server หลายๆตัว ลงในเครื่อง Server ตัวเดียว หรือที่เรียกกันว่า VM (Virtual Machine)
และเมื่อ Internet เร็วและแรงขึ้น ก็ได้เกิดบริการที่เรียกว่า Cloud Computer ซึ่งใน Cloud เองก็ใช้สถาปัตยกรรมหลายรูปแบบแล้วแต่ผู้ให้บริการ จนมาถึงยุคปัจจุบัน ที่กำลังอยู่ในช่วงของความนิยมใช้ Container อย่างเข่น Docker, Kubernates และก็กำลังก้าวเข้าสู่ยุค Serverless ที่ผมกำลังจะเล่าถึง
สังเกตไหมครับว่า อะไรที่เปลี่ยนไป?…
สิ่งที่เปลี่ยนไปคือ สิ่งที่เราใช้ประมวลผลมันเล็กลงเรื่อยๆ จากเครื่อง Server ย่อยลงมาเหลือแค่ระดับ VM มาเป็น Container รวมถึงการจัดการเรื่องเหล่านี้ก็ถูกผลักไปให้ทางผู้ให้บริการดูแลมากขึ้น จากที่ต้องดูแลเรื่อง Hardware + Network + Middleware + Application ก็เหลือเพียงแค่โฟกัสเรื่อง Application อย่างเดียว (ส่วน SaaS มันคือการไปใช้ระบบของคนอื่นเลย ไม่ต้องทำเอง ไม่ต้องดูแล)
ซึ่ง ผมไม่รู้ว่าใครเริ่มก่อนกัน ระหว่าง Hardware กับ Software แต่มันสอดคล้องกับแนวโน้มการพัฒนา Software ที่นิยมย่อยชิ้นส่วนให้เล็กลง แบบที่เราคุ้นชื่อกันตอนนี้ เช่น Microservice ที่เกิดมาเพื่อลดข้อผิดพลาดที่เป็นผลพวงจากการทำงานที่เกี่ยวข้องกัน รวมถึงจัดการทรัพยากรให้เหมาะสม และก็ลากไปเกี่ยวโยงอีกว่า เพื่อรองรับกับวิธีบริหารจัดการในแบบ Interative and Incremental อย่าง Scrum, DSDM, XP เป็นต้น
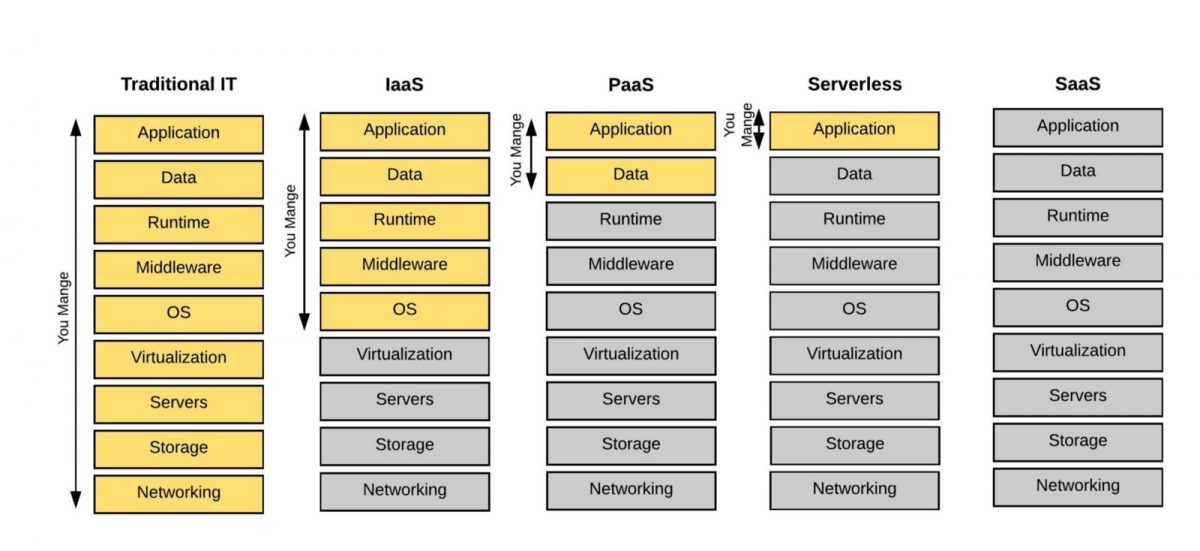
https://medium.com/@sdorzak/why-serverless-is-the-new-black-e4ff9e9947e0
และเมื่อมันไม่มี Server ให้เราจัดการและดูแล ก็จะเป็นหน้าที่ของผู้ให้บริการ Serverless ต่างๆ ที่จะทำแทนเรา โดยมันจะมีการขยายตัว (Scale out) หดตัว (Scale down) เพื่อจัดทรัพยากรย์ต่างๆ ให้รองรับปริมาณการทำงานตามความเหมาะสมแบบอัตโนมัติ และคิดค่าใช้จ่ายตามการใช้งานจริง
AWS Lambda คืออะไร?
เป็น Serverless Platform ที่สร้างโดย Amazon ตั้งแต่ November 2014 โดยมีรูปแบบเป็น FaaS (Function-as-a-Service) หรือว่าง่ายๆ คือ Lambda 1 ตัวที่ถูกสร้างชั่วคราวเพื่อมาใช้งาน จะมีเพียง 1 Function หรือหนึ่งการทำงานเท่านั้น (ประมาณว่า Server 1 ตัว เก็บแค่ 1 Function)
และมันได้ออกแบบมาเป็น EDA (Event-driven architecture) คือ ต้องมี Event Trigger ไปเรียกมันขึ้นมาใช้งาน ไม่สามารถทำงานได้ด้วยตัวเอง
ตอนนี้รองรับภาษายอดนิยม อย่าง Node.js, Python, Java, Go, Ruby และ C# (.NET Core) และถ้าใครใช้ PHP แม้จะยังไม่รองรับ แต่ก็สามารถทำ PHP Custom Runtime เองได้
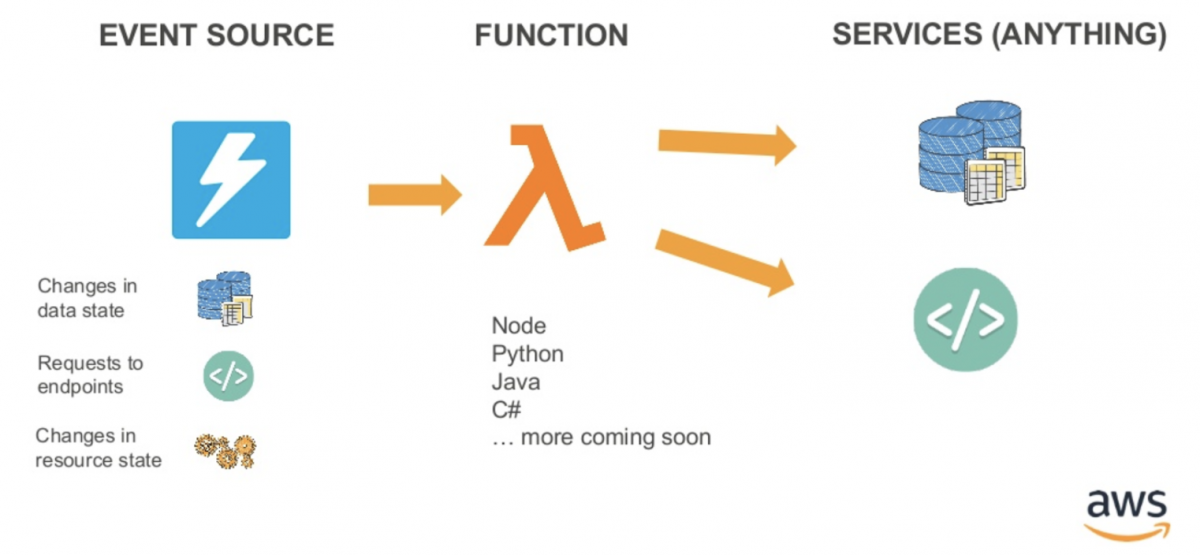
https://www.slideshare.net/AmazonWebServices/deep-dive-on-aws-lambda
รายละเอียดอื่นๆ ไปดูเพิ่มเติมได้ที่ https://aws.amazon.com/lambda/ ครับ
Serverless ทำงานอย่างไร?
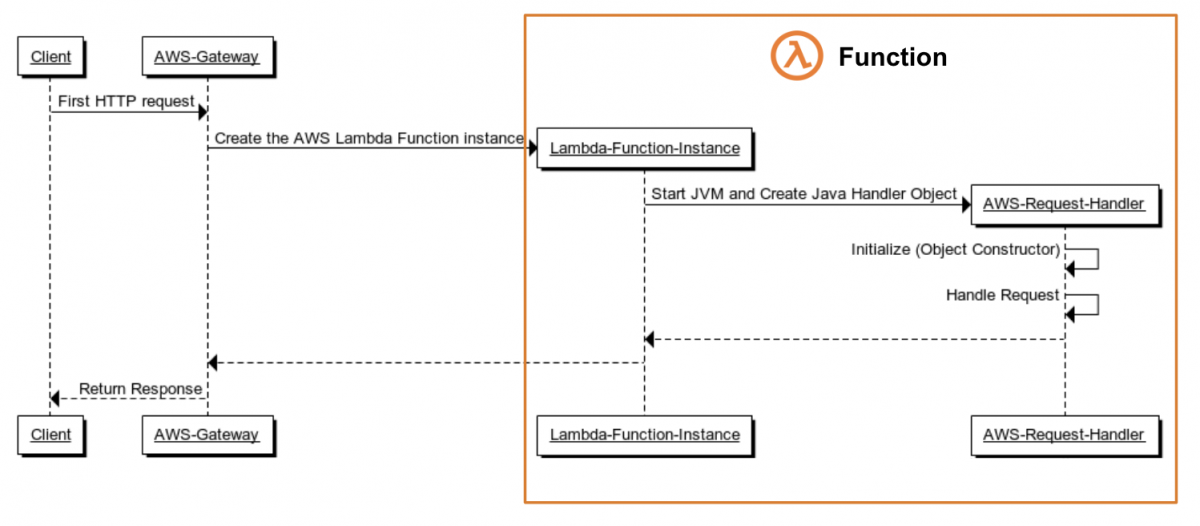
https://medium.com/@chrishantha/ballerina-services-in-serverless-world-b54c5e7382a0
ตามที่เกริ่นไปก่อนหน้า เมื่อมันไม่มี Server เปิดทิ้งไว้ มันจึงต้องมีอะไรบางอย่างไปสะกิดเพื่อปลุกมันให้ตื่น (หรือที่เรียกว่า Event Trigger) โดยส่วนมากแล้วก็ถูกนำไปใช้กับ API Gateway เพื่อทำเป็น API Backend
โดยเมื่อมีใครเรียกใช้มัน มันก็จะสร้าง Server (หรือเรียกว่า Instant) ขึ้นมาเพื่อประมวลผลอะไรบางอย่าง และส่งผลลัพธ์ให้เรา และเมื่อไม่ได้ใช้บริการมันในระยะเวลาหนึ่ง มันจะกลับไปหลับเหมือนเดิม (หรือเรียกว่า Idle, Sleep) เพื่อรอการเรียกอีกครั้ง ซึ่งในขณะที่มันหลับอยู่ก็จะไม่คิดค่าบริการกับเรา
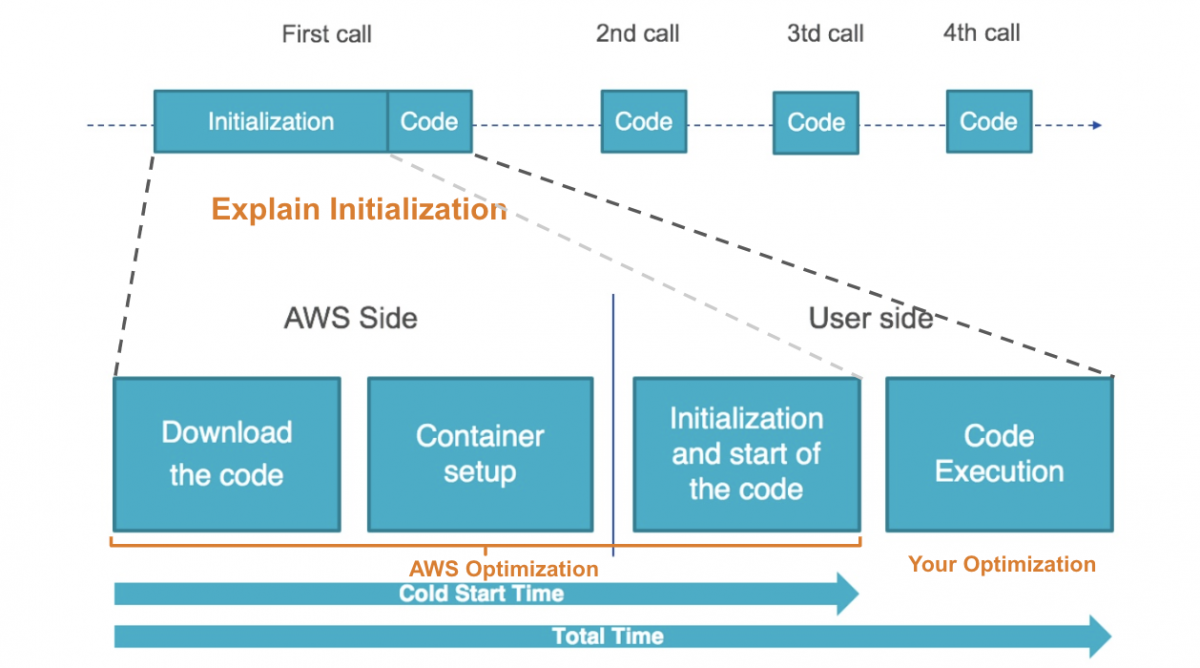
ลงในรายละเอียดอีกนิด และสำคัญมากๆ คือ ตอนมัน Initial เพื่อสร้าง Server ขึ้นมา มันจะโหลดโค้ดของเรา และทำการติดตั้งนั่นโน่นนี่ และรันโค้ดของเราเพื่อมาทำงาน
ที่มันสร้างและติดตั้งต่างๆนี่เอง เรียกว่าช่วง Cold Start ผมให้ข้อสังเกตว่า ตรงนี้เป็นปัญหาหนึ่งที่ทำให้กินเวลาการประมวลผลเพิ่มขึ้น แต่จะเกิดกับครั้งแรกที่รันเท่านั้น พอรันซ้ำอีกครั้ง ในเวลาไล่เลี่ยกัน (หรือก่อนที่มันจะหลับ) มันจะ execute code อย่างเดียว ก็จะทำให้เร็วตามที่โค้ดเราทำงานจริงๆ
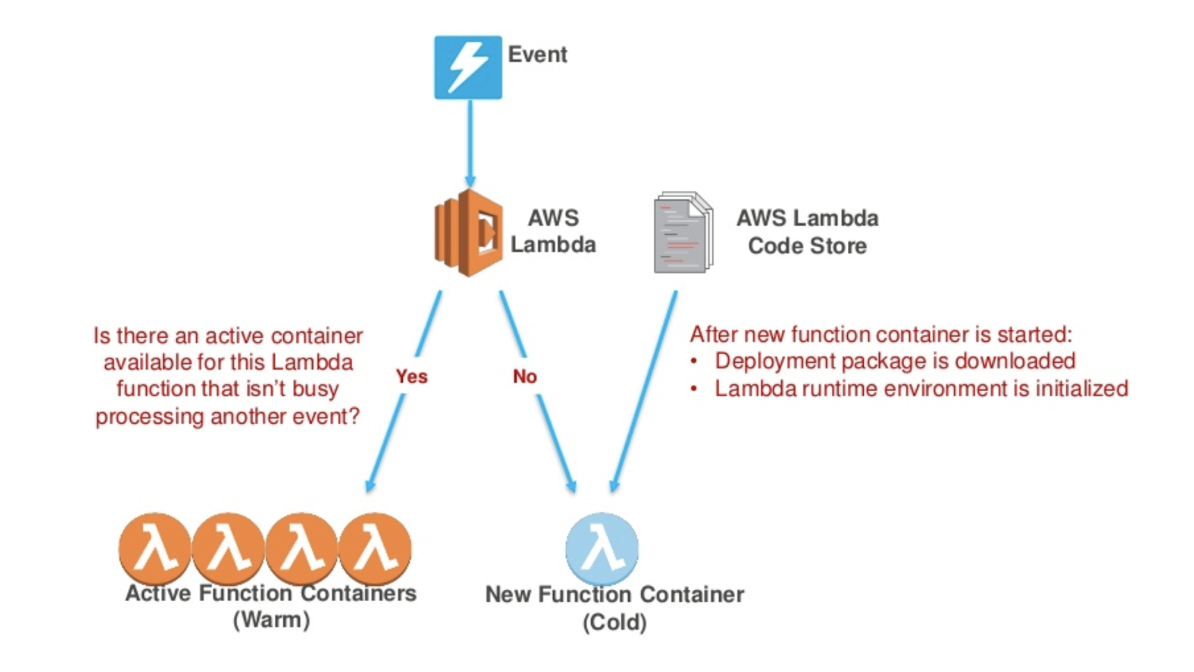
https://www.slideshare.net/AmazonWebServices/srv310designing-microservices-with-serverless
ถามว่า Cold Start กินเวลานานขนาดไหน ต้องบอกว่าเป็นหลักวินาที ยิ่งโค้ดใหญ่มาก จัดสรร Memory ให้น้อย ก็ยิ่งใช้เวลานาน ตรงนี้เป็นจุดหนึ่งที่ต้องคิดเยอะๆ เพราะมีผลกับผู้ใช้งานคนแรก และค่าใช้จ่ายที่ตามมา
ปล. ผมโดนถามบ่อยๆว่า นานแค่ไหนที่ Server จะเข้าสู่โหมด Idle? จากที่เจอเอง ใช้ Server Singapore ผมลุกไปเข้าห้องน้ำ 5-10 นาที กลับมาก็รู้สึกช้าแล้วครับ แต่กับที่ไปหาอ่านของฝรั่ง น่าจะใช้ Server ทวีปอื่น บางคนบอก 15 นาที บางคนบอก 45 นาที ผมจึงเชื่อว่าทวีปน่าจะมีผลกับเวลา Idle
iFew
การทำงานแบบ Continuous Scaling
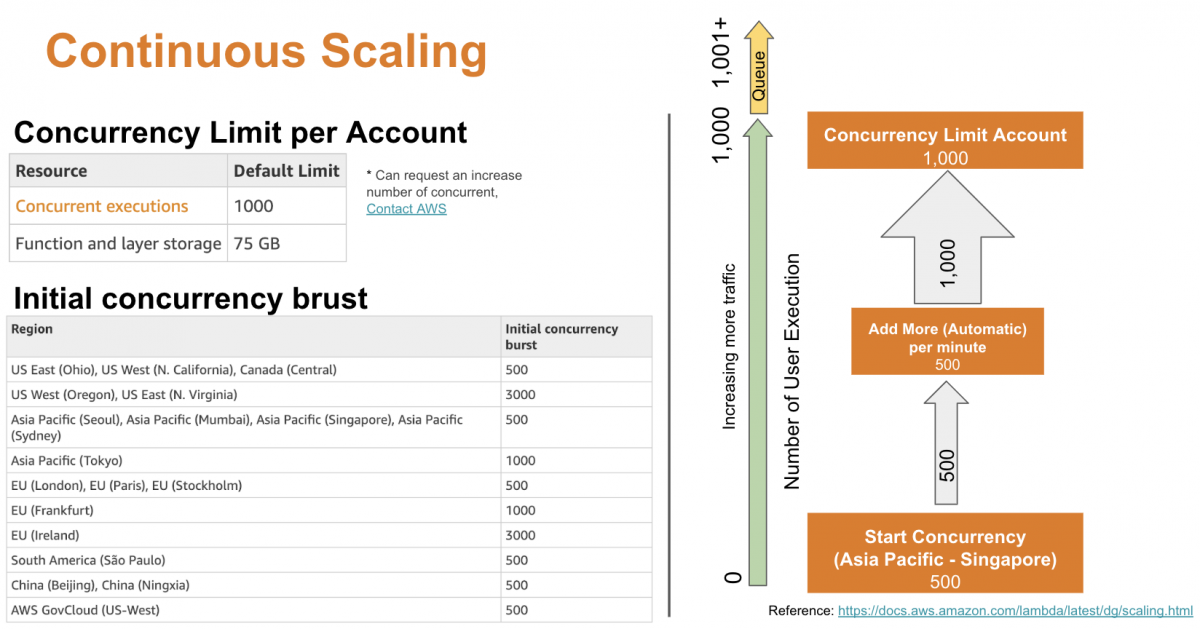
สั่งเกตว่าใช้คำว่า Continuous Scaling ไม่ใช่ Auto Scaling แบบที่เคยทำกับ Cloud ทั่วไป แล้วมันทำงานอย่างไรล่ะ?
อ้างอิงจากเอกสาร Understanding Scaling Behavior ของ Amazon ได้บอกไว้ว่า AWS Lambda มีการ Initial ครั้งแรกก็จะรองรับ Concurrency ได้จำนวนหนึ่ง แต่จะแตกต่างกันตามแต่ละทวีปที่เราใช้บริการ
เช่น ผมเลือกใช้ของ Singapore ดังนั้นการสร้าง Server ขึ้นมาครั้งแรก มันจะรองรับ Concurrency ที่ 500 และถ้ามีปริมาณผู้ใช้มากขึ้นเรื่อยๆ มันจะทำการเพิ่ม Concurrency ให้ครั้งละ 500 ในทุกๆ 1 นาที จนกว่าจะชนเพดาน Limit ที่เรามี (ซึ่งในภาพตัวอย่าง คือ รองรับได้ที่ 1,000 Concurrency พร้อมกัน ซึ่งทุกคนจะได้ค่ามาตรฐานเป็นเท่านี้ ยกเว้นไปอีเมลขอปริมาณเพิ่มจากทาง Amazon)
โดย Concurrency ทั้งหมดที่เรามีนั้น Amazon จะกระจายให้กับทุก Function ตามการใช้งานจริง เช่น Function A มีการเรียกใช้ 125 Concurrency จะทำให้ Function อื่นๆ ทั้งหมดแย่งกันใช้จาก 875 Concurrency ที่เหลือ ดังนั้น Amazon จึงมีฟีเจอร์ให้เราจอง Concurrency ให้กับ Function ได้ว่า ต้องมีเหลือให้ใช้เสมอ ในจำนวนเท่าไร
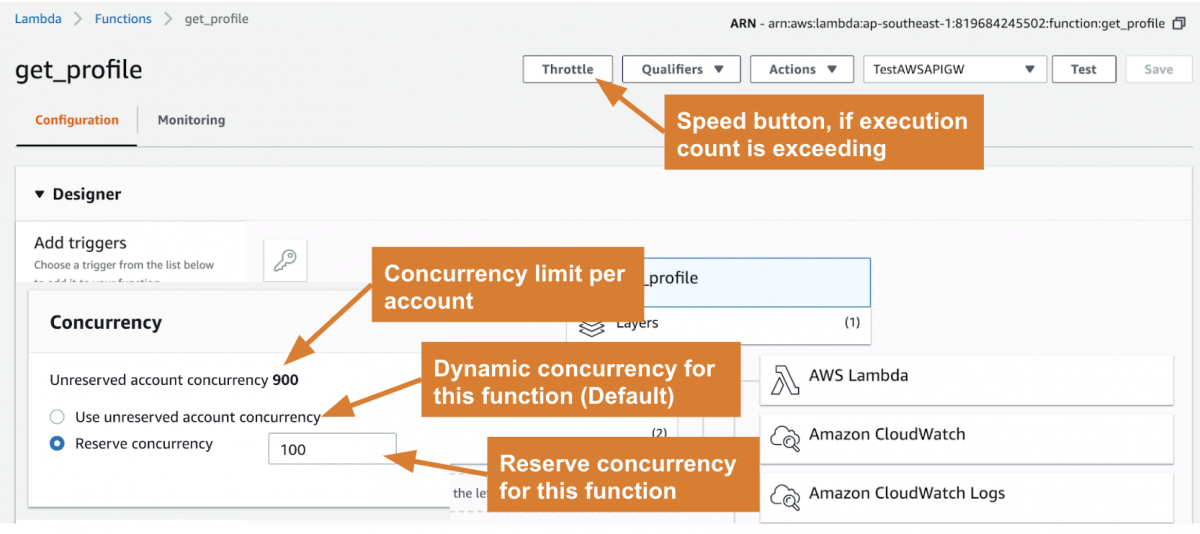
รวมไปถึง หากพบว่ามีการประมวลผลแปลกๆ ทำงานนานผิดปกติ หรือพบว่ามีการ Reuqest มากผิดปกติ ซึ่งจะส่งผลกับค่าใช้จ่ายที่มากขึ้น เราสามารถปิดการทำงานชั่วคราวได้ด้วยการลด Concurrency ให้เหลือศูนย์ (Throttle)
Serverless เอาไปใช้งานใดได้บ้าง?
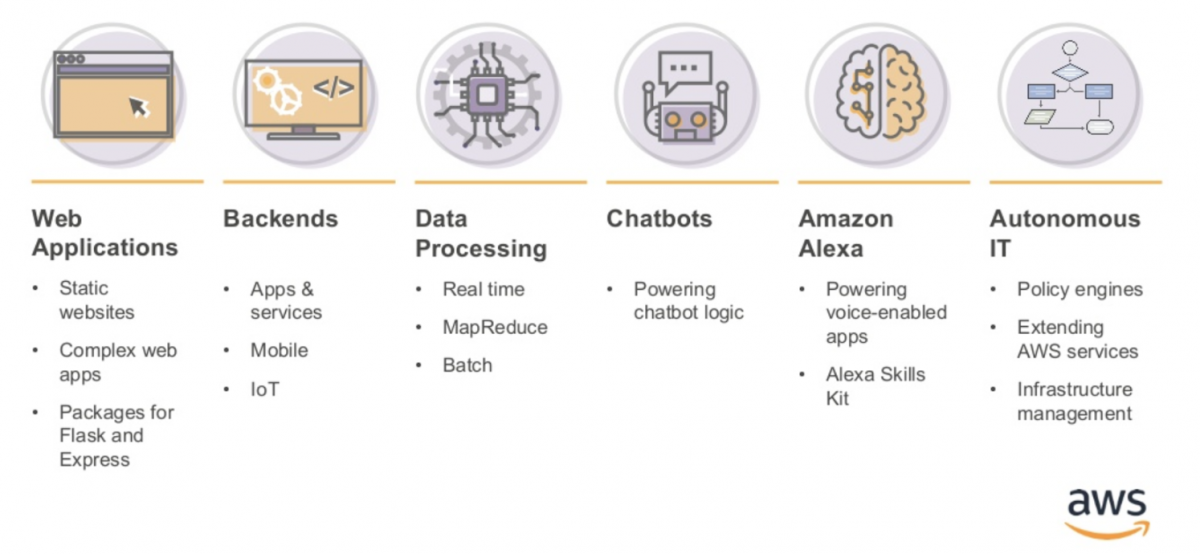
https://www.slideshare.net/AmazonWebServices/deep-dive-on-aws-lambda
อ้างอิงจากรูป แบ่งตามประเภทแล้ว มันสามารถใช้งานได้ในหลากหลายรูปแบบ แต่เราต้องเข้าใจธรรมชาติมันก่อนนะว่า มันเกิดขึ้น ตั้งอยู่ ดับไป คิดเงินตามการใช้งานจริง และต้องมี Event Trigger ไปปลุกให้มันตื่น
จากความคิดเห็นส่วนตัวของผม ถ้าระบบที่เราจะนำไปใช้ มีความจำเป็นต้องใช้งานตลอดเวลา บางทีการมี Server ปกติ เปิดทิ้งไว้ อาจจะมีค่าใช้จ่ายที่ถูกกว่า และจัดการได้ง่ายกว่า หรือจะพิจารณา API บางตัวไปใช้เป็น Serverless ก็เพียงพอ ไม่ต้องทำทั้งระบบ ทั้งนี้ ไม่มีใครบอกได้ว่าควรใช้ส่วนไหนบ้าง อยู่ที่ผู้เข้าใจระบบเท่านั้น
ข้อดี/ข้อเสียของ Serverless
https://www.slideshare.net/AmazonWebServices/deep-dive-on-aws-lambda
หลังจากเข้าใจแล้วว่าคืออะไร ลองมาพิจารณาข้อดีข้อเสียและชั่งน้ำหนักก่อนจะตัดสินใจใช้งานดูนะครับ
- ข้อดี
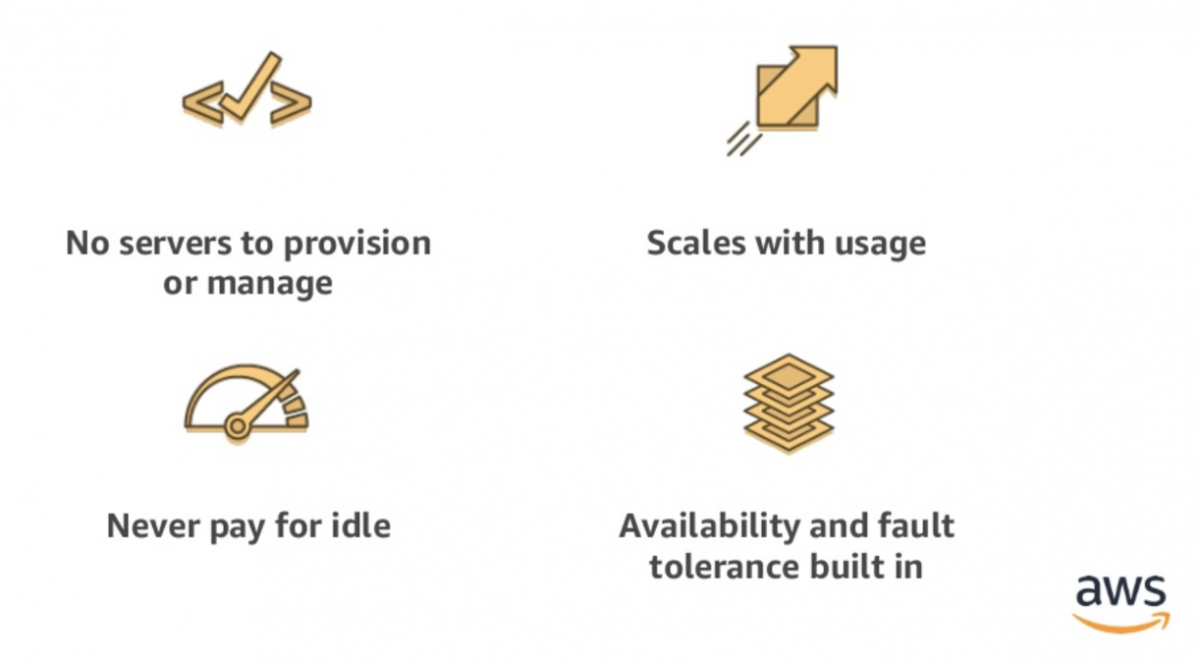
- ลดค่าใช้จ่าย เพราะจ่ายเท่าที่ประมวลผลจริง ไม่มีเปิด Server ทิ้งไว้
- ไม่มี Server ให้ต้องดูแลและจัดการ
- Scale ได้ต่อเนื่องตามการใช้งานจริง และอัตโนมัติ
- ข้อเสีย
- เรื่องของการ Initial Server ครั้งแรก (Cold Start) จะใช้เวลานิดหนึ่ง
- ทรัพยากรที่จำกัด (Memory 128MB-3GB, Limit Concurrency 1,000/region/account)
- แนวคิดการออกแบบซอร์ฟแวร์ที่จะยากขึ้น ว่าทำอย่างไรให้หั่นการทำงานใหญ่ๆ เป็นการทำงานย่อยๆ
- การทดสอบใน Local Machine ยาก จำเป็นต้องมี Unit Test (และก็เขียน Unit Test ยากเช่นกัน)
- Monitoring และ debugging ค่อนข้างยาก (ทำได้แต่เสียเงินเพิ่ม อย่าง AWS Lambda ต้องเปิดบริการอย่าง AWS Cloudwatch, AWS X-Ray ในการดูเพิ่มเติม)
- OS vulnerabilities ถูกดูแลโดยผู้ให้บริการ Serverless, เราอัพเดท หรือแก้ไขอะไรเองไม่ได้
แถม: Serverless สามารถลดค่าใช้จ่ายได้จริงหรือ?
เป็นข้อดีและก็เป็นข้อสงสัยว่า Serverless สามารถลดค่าใช้จ่ายได้จริงหรือ ซึ่งผมคิดว่าอยู่ที่การพิจารณาเอาไปใช้ ว่าทดแทนส่วนไหนแล้วลดค่าใช้จ่ายได้ ซึ่งไม่มีใครตัดสินใจให้ได้ แต่ผมจะขออธิบายโครงสร้างราคาและตัวอย่าง ของ AWS Lambda ไว้เป็นแนวทาง
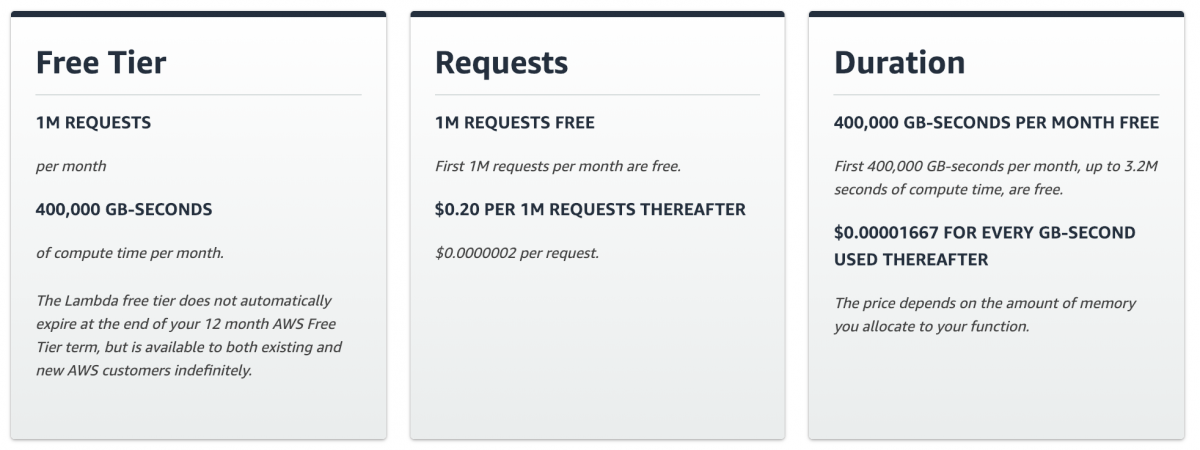
โดย AWS Lambda มีการคิดเงินจากสองส่วน คือ
- คิดตามจำนวนการเรียกใช้ (Requests)
- ให้ฟรี 1 ล้าน Requests ทุกเดือน
- 1 ล้านต่อไป คิดที่ $0.20 (~6 บาท)
- คิดตามระยะเวลาประมวลผล (Duration Time)
- ให้ฟรีประมวลผล 400,000 GB-Seconds* ทุกเดือน
- ทุกๆ 1 GB-Seconds คิดที่ $0.00001667 (~0.00055011 บาท)
- ทุกครั้งที่มีประมวลผล จะปัดเศษขึ้นที่หลัก 100ms (เช่น 15237ms = 15300ms, 97.12ms = 100ms, 0.43ms = 100ms)
ปล. GB-Seconds ย่อมาจาก Gigabyte second หมายความว่า การประมวลผลโดยใช้ Memory จำนวน 1 Gigabyte ใน 1 วินาที (เช่น เราจัดสรรให้ฟังก์ชั่นเราทำงาน 3GB แต่มีการประมวลผล 2 วินาที ก็เท่ากับการรันครั้งนี้ใช้งานไป 6 GB-Seconds)
iFew
เรื่อง Requests น่าจะเข้าใจได้ แต่เรื่อง Duration Time กับ Memory อาจจะยังงงๆ ให้ดูภาพด้านล่างนี้ครับ
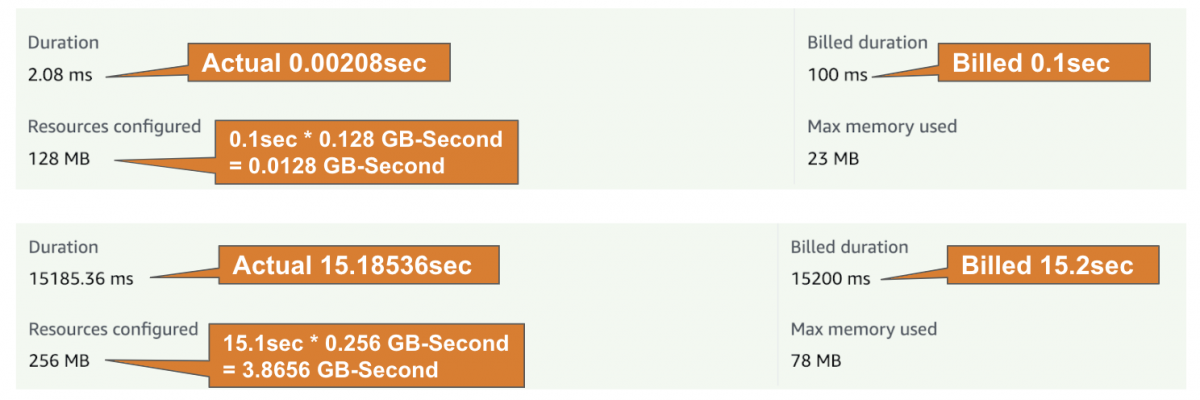
ในหน้าของ AWS Lambda เองจะมีข้อมูลบอกแบบนี้ ว่า Duration Time ของการประมวลผลจริงๆ เท่าไร (Actual) และคิดเงินที่เท่าไร (Billed) จากนั้นเอา Memory ที่เราจัดสรรให้กับ Server เรา มาคำนวณเพื่อหาว่า GB-Second ของการทำงานครั้งนี้เป็นเท่าไร
โจทย์ตัวอย่าง
ถ้ามีฟังก์ชั่นชื่อ get_product() โดยเราจัดสรร Memory ให้ 128MB มีการเรียกใช้งาน 30 ล้านครั้งใน 1 เดือน ซึ่งแต่ละครั้ง ใช้เวลาประมวลผล 200ms

ในเดือนนั้น เราต้องจ่ายค่าประมวลผล get_product() ทั้งหมด $11.63 โดยคิดเป็นค่า Requests $5.80 และค่าประมวลผล (Compute) $5.83
วิธีการคิด ค่า Requests
สูตรคือ Total requests – Free tier request = Billable requests
แทนค่า 30M requests – 1M free tier requests = 29M Monthly billable requests
สรุป Monthly request charges = 29M * $0.2/M = $5.80
วิธีการคิด ค่า Compute (Duration Time)
สูตรคือ Total compute (seconds) = 30,000,000 * 0.2sec = 6,000,000 seconds
แปลงเป็น GB-Second Total compute (GB-s) = 6,000,000sec * 128MB/1024 = 750,000 GB-s
หา GB-Second ที่ต้องจ่าย 750,000 GB-s – 400,000 free tier GB-s = 350,000 GB-s
สรุป Monthly compute charges = 350,000 * $0.00001667 = $5.83
สรุป
หลังจากที่ผมได้เล่น AWS lambda แล้ว ผมชอบคอนเซ็ปมันนะ รู้สึกว่ามันกำลังพาเราก้าวเข้าสู่ยุคสมัยใหม่ (ขนาดนั้นเลยจริงๆ) แล้วมันก็มาพร้อมกับเรื่องที่เราต้องเรียนรู้อีกมากมาย เพราะจากความรู้สึกส่วนตัวของผม ผมรู้สึกเห็นภาพของ Unit Test และการ Design Architectuer อย่าง Microservice ได้ชัดเจนมาก เพราะด้วย Platform มันบีบให้เราต้องทำ เพราะถ้าเราไม่ทำ มันมีค่าใช้จ่ายโดยตรงที่เราต้องเสีย อย่างจำนวน Request และ Duration Time ชัดเจน (ก่อนหน้านั้น เป็นค่าใช้จ่ายแฝงของการบริหารโปรเจ็คที่เราเห็นภาพไม่ค่อยชัด อย่างเข่นการไม่มี Test)
Slide
อ้างอิง
- รูปปกจาก http://alena-vysotskaya.ru/stone-wall-wallpapers/img644822B2784
- รูปอื่นๆ จาก ลิงค์ที่อ้างอิงใต้รูป