

แจกโค้ด Second Brain with OpenClaw (Open Source) – ระบบจัดการความรู้ส่วนตัวด้วย AI Agentic
เมื่อสัปดาห์ก่อน ผมเขียนบทความเรื่อง ลอง Implement ใช้ Second Brain กับน้องกุ้ง OpenClaw เล่าให้ฟังว่าทำไมถึงสร้าง Second Brain ขึ้นมา ปัญหาที่ bookmark แล้วไม่กลับมาดู หรือมีไอเดียดีๆ จดแล้วหายไป หาไม่เจอ ฯลฯ
ตอนนั้นเป็นแค่ prototype ใช้เอง แต่ตอนนี้ผมพัฒนาต่อจนเป็น full-featured system และตัดสินใจ open source ให้ทุกคนลองไปเล่นดู และพัฒนาต่อครับ
👉 GitHub Repository: github.com/ifew/Second-Brain-with-OpenClaw
บทความนี้จะพาไปดูว่า Second Brain ตัวนี้มีอะไรบ้าง ติดตั้งยังไง แล้วใช้งานจริงเป็นยังไง มาดูกัน!
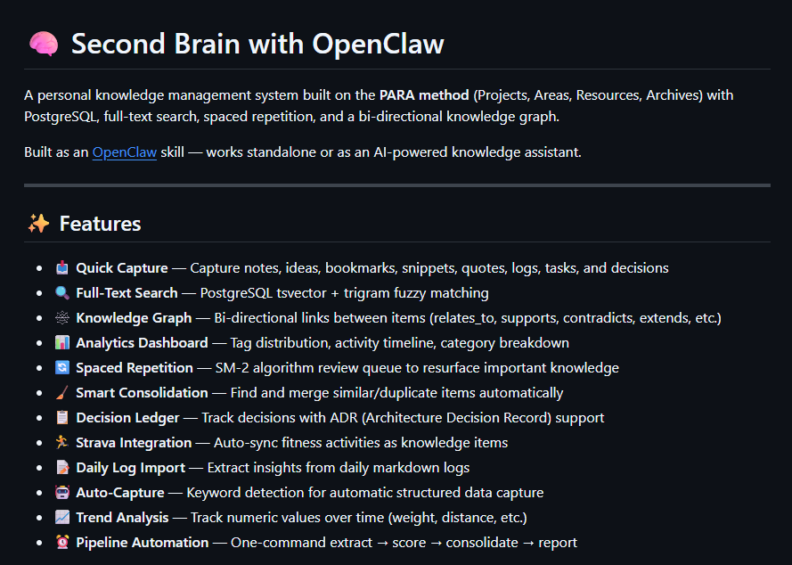
Features ทั้งหมดที่มี
จากบทความก่อนที่เล่าแค่ concept กับ schema เบื้องต้น ตอนนี้ผมลองเพิ่มนั่นโน่นนี่จนมีฟีเจอร์ น่าจะค่อนข้างครบทุกด้าน ประมาณ 10 ฟีเจอร์หลักๆ ครับ ดังนี้:
1. PARA Method Organization
จัดหมวดหมู่ข้อมูลตามแนวคิด PARA ของ Tiago Forte:
- Projects — สิ่งที่กำลังทำอยู่ มี deadline
- Areas — ความรับผิดชอบต่อเนื่อง (เช่น สุขภาพ, การเงิน)
- Resources — ข้อมูลอ้างอิงที่สนใจ
- Archives — สิ่งที่เสร็จแล้วหรือไม่ active
2. Full-text Search (ไทย + English)
ค้นหาด้วย tsvector + pg_trgm trigram similarity ทำให้ค้นได้ทั้งภาษาไทยและอังกฤษ สะกดผิดนิดหน่อยก็ยังเจอ!
3. Knowledge Graph
เพิ่งไปฟังเพื่อนแชร์มา เลยจดๆไว้ มาทำต่อ เป็นเรื่องของการเชื่อมโยงข้อมูลให้ถึงกัน โดยมี 8 ประเภท
related— เกี่ยวข้องกันsupports/contradicts— สนับสนุน/ขัดแย้งextends— ต่อยอดจากdepends_on— ขึ้นอยู่กับparent— หัวข้อแม่reference— อ้างอิงinformed_by— ตัดสินใจโดยอ้างอิงจาก (ใหม่ใน v3)
รองรับ depth-2 traversal — ค้นหาความเชื่อมโยง 2 ระดับได้
4. Spaced Repetition (SM-2 Algorithm)
ระบบ review queue ที่ใช้ SM-2 algorithm (เหมือน Anki) เพื่อให้ทบทวนข้อมูลสำคัญในจังหวะที่เหมาะสม ป้อน quality score 0-5 แล้วระบบจะคำนวณว่าควร review อีกเมื่อไหร่
5. Decision Ledger (ADR Format)
ข้อนี้ก็ได้จากการฟังเพื่อนเล่าอีกเช่น กัน 555 ว่าเขามีระบบบันทึกการตัดสินใจด้วย ก็เลย implement feature นี้เพิ่มอีกหน่อย โดยใช้รูปแบบ Architecture Decision Record (ADR) ที่ทำๆกันนี่แหละ:
- บันทึก problem statement, options ที่พิจารณา, เหตุผลที่เลือก
- Track status:
proposed → accepted → deprecated → superseded - ตั้ง review schedule ให้กลับมาทบทวนอัตโนมัติ
- เชื่อมโยงกับ knowledge items อื่นๆ ได้
- ใช้ได้ทั้ง technical decisions และ strategic/life decisions
6. Relevance Scoring (Time-Decay)
ตัวนี้ผมไปเจอฟีเจอร์ Memory Scoring ที่ jugaad-lab/second-brain ทำไว้ น่าสนใจดี เขาทำคำนวณความสำคัญของข้อมูลด้วยสูตร:
score = base * (0.5 ^ (days_old / half_life)) * priority_boostข้อมูลเก่าจะค่อยๆ ลด relevance ลง แต่ถ้าตั้ง priority สูงไว้ก็จะยังอยู่ด้านบน configurable half-life (default 14 วัน)
7. Consolidation (Duplicate Merging)
ตรวจหา items ที่ซ้ำกันด้วย trigram similarity แล้ว merge เข้าด้วยกัน มี consolidation log เก็บประวัติการรวม
8. Auto-Capture
ตรวจจับ keywords จากการสนทนาแล้ว capture อัตโนมัติ:
- Health — น้ำหนัก, ความดัน, การนอน
- Finance — กองทุนสำรองเลี้ยงชีพ, เงินเดือน, ค่าใช้จ่าย
- Exercise — ข้อมูลการออกกำลังกาย
9. Strava Integration
Sync กิจกรรมจาก Strava ผ่าน OAuth — ดึง distance, pace, elevation, heart rate, calories มาเก็บเป็น log items พร้อม metadata ครบ
ข้อนี้ ใข้งานส่วนตัว ก็เลยแถมติดไปด้วยเลย แหะๆ เราสามารถสั่ง claude code ทำ integration กับระบบอื่นๆ ได้นะ ที่เราไม่อยากกรอกเอง แต่ให้ดึงข้อมูลอัตโนมัติมาบันทึกให้เลย
10. Automated Pipeline
4-step pipeline ที่รันอัตโนมัติ:
- Extract — ดึง decisions, insights, tasks, learnings จาก daily logs
- Score — คำนวณ relevance scoring ใหม่
- Consolidate — หาและรวม duplicates
- Report — สร้างรายงานสรุป
Database Schema
ระบบใช้ PostgreSQL กับ 10 tables ที่ออกแบบมาอย่างดี:
| Table | หน้าที่ |
|---|---|
sb_items | Core items — 8 types, 5 statuses, relevance score |
sb_categories | PARA categories |
sb_tags | Hierarchical tags (รองรับ parent_id) |
sb_sources | Knowledge sources (URL, book, conversation, file, telegram) |
sb_item_tags | Item-tag junction table |
sb_links | Knowledge graph edges (8 link types) |
sb_reviews | SM-2 spaced repetition queue |
sb_decisions | Extended decision metadata |
sb_consolidations | Merge history |
sb_daily_imports | Daily log import tracking |
Installation — ติดตั้งยังไง
Step 1: Clone Repository
git clone https://github.com/ifew/Second-Brain-with-OpenClaw.git
cd Second-Brain-with-OpenClawStep 2: ติดตั้ง PostgreSQL + Extensions
# ติดตั้ง PostgreSQL (ถ้ายังไม่มี)
sudo apt install postgresql postgresql-contrib
# เปิดใช้ extensions ที่ต้องการ
sudo -u postgres psql -c "CREATE DATABASE few;"
sudo -u postgres psql -d few -c "CREATE EXTENSION IF NOT EXISTS pg_trgm;"Step 3: สร้าง Tables
# สร้าง schema หลัก
psql -d few -f create_tables.sql
# รัน v2 migration (relevance scoring, consolidation, pipeline)
psql -d few -f migrate_v2_features.sql
# รัน v3 migration (Decision Ledger)
psql -d few -f sql/migrations/002_decision_ledger.sqlStep 4: ติดตั้ง Python Dependencies
pip install psycopg2-binaryแค่นี้ก็พร้อมใช้แล้ว! ไม่มี dependency เยอะเพราะตั้งใจ keep it simple
Integration กับ OpenClaw
Second Brain ถูกออกแบบมาให้ทำงานร่วมกับ OpenClaw agent system ได้อย่างราบรื่น:
Skill-based Architecture
ใน OpenClaw ระบบ Second Brain ถูก register เป็น skill ที่ agent สามารถเรียกใช้ได้ ทำให้สามารถ:
- สั่งด้วยภาษาธรรมชาติ — บอก agent ว่า “จดไว้ว่า…” หรือ “ค้นหาเรื่อง…” agent จะเรียก Second Brain tools ให้อัตโนมัติ
- Auto-capture จาก conversation — agent ตรวจจับ insights, decisions, tasks จากบทสนทนาแล้วบันทึกเข้า Second Brain ให้เลย
- Daily extraction — ดึงข้อมูลจาก daily memory logs เข้า Second Brain ผ่าน automated pipeline
- Strava sync อัตโนมัติ — sync ข้อมูลออกกำลังกายเข้ามาเป็น knowledge items
10 CLI Tools
มี command-line tools ครบชุดที่ทั้ง agent และคนใช้ได้:
capture.py— Quick capture to inboxsearch.py— Full-text + trigram searchquery.py— Trend analysis, activity reportsreview.py— SM-2 review queuelink.py— Knowledge graph CRUDstats.py— Dashboard + analyticsextract.py— AI memory extractionconsolidate.py— Duplicate detection + mergingpipeline.py— Full automated pipelinedecision.py— Decision Ledger management
ตัวอย่างการใช้งานจริง
Capture ข้อมูลเข้า Inbox
# จดโน้ตด่วน
python3 tools/capture.py "Trail conditions at Doi Inthanon" --tags trekking chiang-mai --priority 2
# Capture จาก stdin (pipe ได้)
echo "New gear recommendation" | python3 tools/capture.py --stdin --type idea --tags gearค้นหาข้อมูล
# ค้นหา full-text
python3 tools/search.py "inthanon" --limit 5
# ค้นหาด้วย tag + text
python3 tools/search.py "gear" --tag trekking --sort relevanceบันทึก Decision
# บันทึก technical decision
python3 tools/decision.py create \
--title "Use PostgreSQL for Second Brain storage" \
--problem "Need persistent, queryable storage for knowledge items" \
--options "SQLite|PostgreSQL|MongoDB" \
--decision "PostgreSQL — already running for post tracking" \
--rationale "Reuse existing infrastructure, full-text search with tsvector" \
--type technical
# ดู decisions ที่ accepted
python3 tools/decision.py list --status accepted --type technical
# ดู decisions ที่ต้อง review
python3 tools/decision.py review --dueKnowledge Graph
# เชื่อมโยง 2 items
python3 tools/link.py create 1 2 --type supports --note "Evidence for conclusion"
# ค้นหา items ที่เกี่ยวข้อง 2 ระดับ
python3 tools/link.py related 1 --depth 2
# ขอ suggestion ว่าควรเชื่อมโยงกับอะไร
python3 tools/link.py suggest 1Review Queue
# ดู items ที่ต้อง review
python3 tools/review.py due
# review เสร็จ ให้คะแนน quality 0-5
python3 tools/review.py complete 42 --quality 4Automated Pipeline
# รัน full pipeline: extract → score → consolidate → report
python3 tools/pipeline.py
# preview ก่อน (ไม่เปลี่ยนแปลงข้อมูล)
python3 tools/pipeline.py --dry-run
# รันแค่ step เดียว
python3 tools/pipeline.py --step extractPython API
from second_brain import SecondBrain
sb = SecondBrain()
# Capture
item = sb.capture("ไอเดียใหม่สำหรับ blog", item_type="idea", tags=["blog", "content"])
# Search
results = sb.search("trekking gear", limit=10)
# Decision
decision = sb.capture_decision(
title="Migrate from CSV to PostgreSQL",
problem="CSV files have race conditions",
options=["Keep CSV", "SQLite", "PostgreSQL"],
decision="PostgreSQL",
rationale="Already running, supports concurrent access",
decision_type="technical",
review_days=90,
)
# Link decision to related items
sb.link_decision_to_items(decision['id'], [10, 15, 22])
# Stats
sb.stats()
sb.weekly_review()Version History
- v1 — PARA organization, full-text search, knowledge graph, spaced repetition, Strava integration, auto-capture
- v2 — เพิ่ม relevance scoring (time-decay), consolidation, AI extraction, automated pipeline
- v3 — เพิ่ม Decision Ledger (ADR format),
informed_bylink type,decisionitem type
สรุป
Second Brain with OpenClaw เป็นระบบที่ผมลองทำดูเพื่อจัดการความรู้ส่วนตัว ตั้งแต่ capture ข้อมูล, จัดหมวดหมู่ด้วย PARA, เชื่อมโยงด้วย Knowledge Graph, ทบทวนด้วย Spaced Repetition, ไปจนถึงบันทึก decisions ด้วย ADR format
จุดเด่นคือ ออกแบบมาให้ AI agent อย่าง OpenClaw ใช้งานได้ ไม่ใช่แค่ GUI app ที่คนต้องมานั่งจัดเอง แต่ให้ agent ช่วยจัดการ, ค้นหา, เชื่อมโยง, และทบทวนให้อัตโนมัติ
ทุกอย่าง open source, ใช้แค่ PostgreSQL + Python ไม่มี vendor lock-in, ข้อมูลเป็นของเราเอง 100% ครับ
ลองเอาไปใช้ดูครับ:
ถ้ามี feedback, feature request, หรืออยากช่วยพัฒนาต่อ — เปิด issue หรือ PR ได้เลยครับ! 🙏