
ช่วงนี้เห็นคนรอบตัวทำระบบ Second Brain หลายท่าน เอาไว้เก็บข้อมูลความรู้ที่ตัวเองสนใจ หรืออะไรบางอย่างที่อยากบันทึกไว้จดจำเพื่ออ่านภายหลัง แต่ในโพสต์นี้ผมขอข้ามเรื่องนี้ไปก่อน แต่ที่ผมชอบและให้ความสนใจมากๆ คือ มีการนำแนวคิด LLM Wiki ของ คุณ Andrej Karpathy มาใช้ (บิดาผู้ตั้งชื่อ Vibe Coding) ซึ่งตัวแนวคิดเองค่อนข้างเรียบง่าย แต่มีระบบระเบียบ และการนำมาพัฒนาใช้งาน ก็ง่ายไม่ต่างกัน ซึ่งช่วงนี้หากใครเคยเห็นหรือได้ยินคำว่า Knowledge Graph หรือแอพชื่อ Obsidian แล้วหละก็ เขามักเอามาทำใช้กับ LLM Wiki นี่เอง
Karpathy เขาไม่ได้มอง knowledge base เป็นแค่ถังเก็บไฟล์ แล้วให้ AI LLM ไปค้นคำตอบเท่านั้น แต่เขามองมันเหมือนวิกิที่มี LLM ค่อยๆ ดูแลและบ่มเพาะให้โตและดีขึ้นเรื่อยๆ ซึ่งบทบาทของ LLM จะเปลี่ยนไปทันที จากเครื่องตอบคำถาม ไปเป็นผู้ช่วยจัดระเบียบ สรุป เชื่อมโยง และทำให้ความรู้ทั้งระบบมีความฉลาดขึ้นตามการเพิ่มข้อมูลของเราไปเรื่อยๆ
หมายเหตุ: บทความนี้ฟิวส์กับเอเจ้นชมพู ได้เรียบเรียงจากประสบการณ์การใช้งานจริง และอ้างอิงสรุปที่แปลจากต้นฉบับ เรื่อง Karpathy’s LLM Wiki: The Complete Guide to His Idea File
1. ปัญหาที่แท้จริงไม่ใช่การหาข้อมูล (information) แต่คือการสะสมความเข้าใจ (understanding)
ทุกวันนี้ปัญหาไม่ได้อยู่ที่ข้อมูลหายากอีกแล้วครับ แต่ปัญหาคือเรามีข้อมูลเยอะเกินไป และแต่ละอย่างแยกกันอยู่คนละที่ ไม่ค่อยมีความเชื่อมโยงกัน เวลาจะตอบคำถามหนึ่งสิ่ง สิ่งที่เราทำคือ หาข้อมูลหลายๆ แหล่ง แล้วค่อยเอามาสรุป เรียบเรียงใหม่ทีหลัง ซึ่งค่อนข้างใช้เวลา ในการจัดการความรู้หรือตอบคำถามเราเพียงแค่เรื่องเดียว
สิ่งที่ Karpathy พยายามชี้ให้เห็นคือ ถ้าเราอยากให้การใช้งานแต่ละครั้งสร้างมูลค่าเพิ่มจริงๆ เราควรมีชั้นของความรู้ที่ถูกตีความ (compile) และสรุปไว้แล้วในระดับหนึ่ง ไม่ใช่ให้ทุกคำถามต้องเริ่มจากศูนย์เสมอ นี่แหละคือจุดตั้งต้นของแนวคิด LLM Wiki
2. แม้ RAG จะมีประโยชน์ แต่อาจไม่ใช่คำตอบทั้งหมด
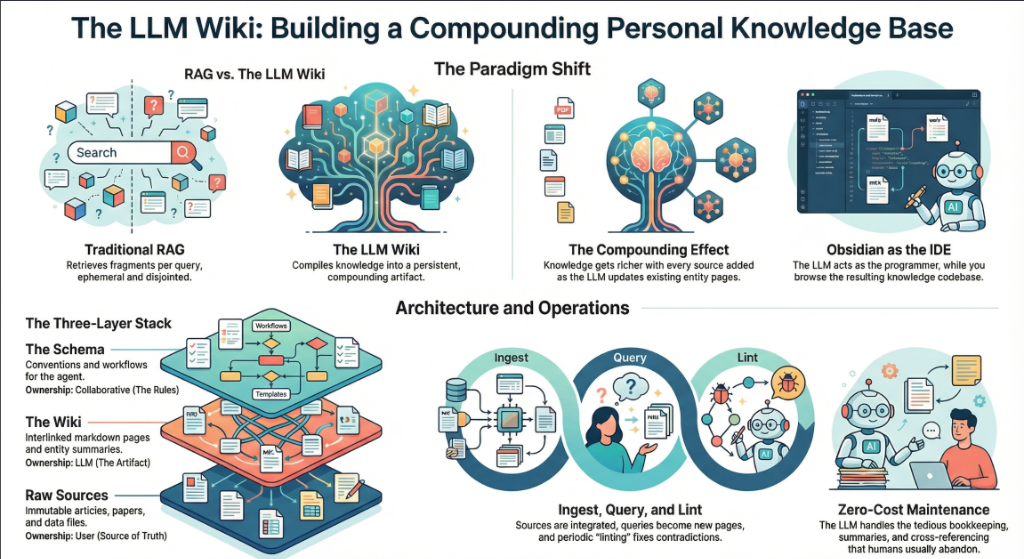
แนวคิดนี้ไม่ได้บอกว่าให้เราทิ้ง RAG นะครับ แต่ตรงกันข้าม มันยังมีประโยชน์มากในงานที่ต้องดึงข้อมูลจากฐานชุดข้อมูลใหญ่ๆ ที่ต้องใช้ความเร็วและยืดหยุ่น แต่ข้อจำกัดของมันคือระบบไม่ได้ดีขึ้นตามจำนวนครั้งที่เราใช้งาน เพราะถังข้อมูลยังอยู่เท่าเดิม แต่มันตอบโจทย์เราได้จากชุดคำถาม (เช่น prompt) กับเครื่องมือที่ไปเรียกใช้ข้อมูลจากมัน (เช่น LLM Model)
RAG จะเก่งเรื่อง retrieval และ on-demand synthesis แต่ LLM Wiki เน้นการสร้าง knowledge artifact ที่อยู่ยาวๆ และได้คำตอบแน่นอนเสมอ พูดง่ายๆ คือ RAG ช่วยให้ “ตอบได้” ส่วน wiki ช่วยให้ “รู้เป็นระบบ” มากขึ้น ถ้าโจทย์คือการสร้างฐานความรู้ระยะยาว ผมคิดว่าจุดนี้สำคัญมาก
3. ชุดข้อมูล LLM Wiki จะมีลักษณะ Compounding
เรียกว่าเป็นหัวใจของระบบ LLM Wiki นี้เลยก็ได้ คือ ความรู้บางประเภทที่เราได้มาจากบทความ แชต หรือหนังสือเป็นเล่มๆ มันควรทำสรุปเพื่อให้เกิดบทความใหม่ ที่เราสามารถกลับมาอ่านซ้ำได้ แต่ในขณะเดียวกัน เมื่อมี data source ในเรื่องเดิมเติมเข้ามาใหม่ หน้าบทความสรุปเดิมก็ควรถูกอัพเดทตามไปด้วย ไม่ใช่ปล่อยให้มันเป็นเรื่องแยกออกจากกัน และสร้างลิงค์กลับมาอ้างอิงเฉยๆ
ผลลัพธ์คือระบบจะเริ่มมีคุณสมบัติ compounding (ไม่แน่ใจจะใช้ภาษาไทยว่าอะไรดี) ไม่ว่าจะเป็นการแตกหัวข้อที่เกียวเนื่องกัน การสรุปในแต่ละหัวข้อ การเชื่อมโยงข้ามหัวข้อ การเห็นข้อขัดแย้ง หรือการมี synthesis page ที่ช่วยย่นเวลาในการทำความเข้าใจเรื่องยากๆ ให้เข้าใจได้ง่ายขึ้น
เจ๋งไหมล่ะ!
4. LLM Wiki กับโมเดลเรียบง่ายแค่สามชุด
เป็นความเรียบง่ายที่ผมชอบ คือ เขาวางข้อมูลไว้แค่ 3 ชุดโดยมี Raw, Wiki, Schema โดย
ชั้นแรก คือ Raw สำหรับเก็บต้นฉบับหรือ source ดิบแบบไม่แก้ไข (Single source of truth) ตั้งแต่ text, pdf, docx, xlsx ที่เราส่งเข้าไป (ingest) อย่างไร มันก็เก็บไว้อย่างนั้น เพื่ออ้างอิง
ชั้นที่สอง คือ Wiki ซึ่งเป็นชั้นที่เกิดจาก LLM ทำการสังเคราะห์ข้อมูลจาก Raw ให้แตกเป็นความรู้ในหัวข้อต่างๆ หาความเชื่อมโยง และสรุปออกมาให้เราอ่าน
ส่วนชั้นที่สาม คือ Schema หรือ กติกาว่าระบบนี้จะ ingest ยังไง จะตั้งชื่อยังไง จะ cross-link ชุดข้อมูลกันยังไง หรือจะ review ยังไง
การแยกสามชั้นนี้ช่วยลดความสับสนได้เยอะมาก เพราะเราไม่ต้องปะปนระหว่างต้นฉบับกับความเห็นสรุป และยังทำให้ LLM มีขอบเขตการทำงานชัดขึ้นด้วยว่าจะไปแตะตรงไหนได้แค่ไหน
5. การ Ingest และ Query
หลายคนมักโฟกัสว่า AI Assistant ตอบคำถามได้ดีไหม แต่ถ้ามองให้ลึกกว่านั้น มันต้องดูตั้งแต่การนำเข้าข้อมูล (Ingest) ซึ่งเป็นงานระดับโครงสร้างเลยครับ เพราะทุกครั้งที่เอา data source ใหม่เข้าไป ระบบต้องรู้ด้วยว่าต้องทำการปรับปรุง knowledge graph ของความรู้เดิมด้วย ไม่ใช่แค่เก็บเอกสารเพิ่มอีกหนึ่งก้อน
ซึ่งถ้า Ingest ดีๆ เราจะได้ประโยชน์มากกว่าการเก็บเอกสารเพิ่ม เพราะระบบจะเริ่มรู้ว่าประเด็นไหนควรแยกเป็นหน้าใหม่ ประเด็นไหนควร merge กับหน้าเดิม และเรื่องไหนเริ่มขัดกันจนควรมี synthesis ใหม่เกิดขึ้น
ส่วนการ Query จะเป็นเหมือนเรื่องการใช้ prompt, ที่ถ้าเราถามได้ดี ข้อมูลก็ออกมาตามที่ต้องการ (แต่ยุคนี้แล้ว ความฉลาดของ LLM ช่วยเราได้เยอะ)
6. ทำไม idea file ถึงน่าสนใจกว่าการเขียนถึงวิธี implementation
อ่านมาถึงตรงนี้ อาจจะผิดหวังนิดหนึ่งที่ทำไมในบทความแปล หรือผมไม่สอนการติดตั้ง LLM Wiki สักทีนึง 555, เพราะผมคิดว่าถ้าเราเข้าใจหลักการ เราสามารถทำเองได้นะ เหมือนที่ผมเคยนั่งอ่าน LLM Wiki และนั่งทำขึ้นมาเอง ก่อนจะพบว่า สิ่งที่ตนเองอ่านนั้น คือ Markdown file ที่โยนไปสั่ง AI implement ได้เลย (ฮาาา)
จริงๆ แล้ว ความหน้าแตกของผม มันสะท้อนถึงความเก่งของคุณ Andrej Karpathy เลยนะ ที่เขียนเล่าเป็นไอเดีย (idea file) ไว้ที่ https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f , ซึ่งถ้าเข้าไปอ่านดู จะพบว่า มนุษย์อย่างเราสามารถอ่านแล้วเข้าใจคอนเซปเขาได้ แต่ในขณะเดียวกัน โยนให้ AI อ่าน มันจะสามารถนำไป Implement ระบบ LLM Wiki ได้ด้วยเช่นกัน
ซึ่งการการแชร์ idea file แบบนี้ ผมว่า เข้าใจง่ายกว่าการเขียนวิธีทำทีละขั้นตอนอีก เพราะมันส่งต่อเจตนา โครงสร้าง และ workflow โดยไม่บังคับว่าทุกคนต้องใช้ Technology stack อะไร, เครื่องคอมฯ แบบไหน หรือ AI อะไร
7. สิ่งที่เปลี่ยนจริงๆ คือบทบาทของมนุษย์
ถ้าเอาแนวคิดนี้มาใช้จริง บทบาทของคนจะไม่ได้อยู่ที่การเขียนสรุปทุกย่อหน้าด้วยตัวเองตลอดเวลา แต่ไปอยู่ที่การคัด data source ดีๆ การถามคำถามให้คม การออกแบบ taxonomy และการตัดสินใจว่าความรู้ชิ้นไหนควรนำเข้ามาสังเคราะห์เป็น Knowledge Based ของเรา
ส่วน LLM จะช่วยทำงานที่ซ้ำและกินแรง เช่น สรุป เชื่อมโยง สร้าง backlinks อัปเดตหน้าที่เกี่ยวข้อง และดูแลความสม่ำเสมอของฐานความรู้
พูดอีกแบบคือมนุษย์ขยับขึ้นไปทำงาน judgement มากขึ้น ส่วน AI จะรับงาน maintenance มากขึ้น
8. เริ่มต้นจากสิ่งเล็กๆ แต่เริ่มให้ถูก
ถ้าถามผม วิธีเริ่มที่ดี คือ อย่าเพิ่งไปคิด infrastructure ใหญ่โตเกินไปครับ เริ่มจากใช้ในเครื่องคอมพิวเตอร์เรานี่เอง ที่ติดตั้ง AI Code อะไรสักตัว เช่น Claude Code, ChatGPT Codex และโยนไฟล์ idea ไปให้สร้างระบบตามคอนเปซนั้น จากนั้นค่อยๆคัดว่าข้อมูลใดเราจะนำเข้า (ingest)
9. สรุปในมุมของผม
สิ่งที่ผมได้จากบทความนี้คือคอนเซปและวิธีคิดในการสร้าง Knowledge Based ด้วยหลักการ LLM WIki ของ คุณ Andrej Karpathy ซึ่งมันไม่ใช่ข้อสรุปนะว่า LLM Wiki ที่เป็น Markdown file จะดีกว่า RAG แต่เป็นการนำเสนอให้เห็นว่า ถ้าเราอยากสร้างระบบความรู้ที่ยิ่งใช้ยิ่งดี เราต้องสนใจเรื่อง structure, ingest และ maintenance มากพอๆ กับเรื่อง model capability หรือเทคโนโลยีที่อาจจะอลังการเกินไป
แต่ในโลกความเป็นจริง เราคงไม่ได้เลือกอย่างใดอย่างหนึ่งหรอกครับ อนาคตถ้าระบบใหญ่มากขึ้น เราอาจจะใช้ทั้ง RAG และ Wiki ร่วมกัน แต่ถ้าโจทย์คือการสร้างฐานความรู้ส่วนตัวหรือทีมที่สะสมความรู้ได้เรื่อยๆ ในระยะยาว แนวคิดแบบ LLM-maintained wiki ของ Karpathy น่าจะเป็นจุดเริ่มต้นที่ดี และง่ายกับใครหลายๆคน รวมถึงผมด้วย
อ้างอิง
- Karpathy’s LLM Wiki: The Complete Guide to His Idea File https://agentpedia.codes/blog/karpathy-llm-wiki-idea-file

