

ตลอดเวลาที่โลกได้มีกระบวนการทำซอร์ฟแวร์ขึ้นมา “การเขียนโค้ด” มักเป็นคอขวดในกระบวน ที่มนุษย์ต้องใช้เวลาในการรังสรรค์โค้ดทีละบรรทัด ทำไปทีละฟีเจอร์ อาศัยแรงกายแรงใจแบบเต็มเหนี่ยว นั่งหลังขดหลังแข็งจนได้ซอร์ฟแวร์ขึ้นมาตัวหนึ่ง แต่เมื่อโลกได้รู้มี AI ที่ฉลาดพอ (สัก 2 ปีที่ผ่านมา) มาอยู่ข้างๆ แป้นพิมพ์ ภาพเดิมก็เริ่มเปลี่ยนเร็วเกินคาด แต่คอขวดไม่ได้หายไปจากกระบวนการพัฒนาซอร์ฟแวร์ มันแค่ย้ายที่จากบรรทัดโค้ดไปซ่อนตัวอยู่ใน requirement ที่คลุมเครือ บริบทและเงื่อนไขทางธุรกิจที่กระจัดกระจาย และคำถามง่ายๆ ที่ตอบยากอย่างไม่น่าเชื่อว่า “สุดท้ายแล้ว เรากำลังสร้างอะไรกันแน่ และขอบเขตมีแค่ไหน”
หมายเหตุ: บทความนี้ฟิวส์กับเอเจ้นชมพู ได้เรียบเรียงและแปลจากต้นฉบับของ Evgeni Rusev เรื่อง Spec-Driven Development: A Practical Guide for AI-Accelerated Teams
วันที่โค้ดอาจไม่ใช่คอขวดอีกต่อไป
แก่นใหญ่ที่สุดของบทความนี้คือการชี้ให้เห็นว่า AI ทำให้การเขียนโค้ดเร็วขึ้นจริง แต่ไม่ได้ทำให้ซอร์ฟแวร์ดีขึ้นตามไปด้วย หรือการตัดสินใจดีขึ้นได้เองโดยอัตโนมัติ ถ้าการตั้งโจทย์ยังไม่ขมุกขมัว ขอบเขตยังไม่ชัดเจน และข้อมูลยังตกหล่น ถึงแม้เราจะมี AI โมเดลเก่งแค่ไหน ผลลัพธ์ก็ยังมีสิทธิ์หลงป่าอยู่ดี
ผู้เขียนบทความ (Evgeni Rusev) มองว่าความสูญเสียครั้งใหญ่ของทีมยุค AI ไม่ได้เกิดตอนพิมพ์โค้ด แต่อยู่ในขั้นตอนก่อนหน้านั้นต่างหาก ตอนที่ทุกคนพยายามปะติดปะต่อว่า ซอร์ฟแวร์ที่ต้องการ จะต้องมีอะไรในเอกสาร requirement บ้าง ใครเคยตกลงอะไรไว้ เงื่อนไขทางธุรกิจคืออะไร ทำไมระบบถึงทำงานแบบนี้ และอะไรคือสิ่งที่ “ทุกคนรู้กันอยู่แล้ว” แต่ไม่มีใครพูดหรือเขียนมันออกมา
ประโยคนี้มักได้ยินบ่อยๆในวงสนทนาของชาวเดฟ และฟังดูเจ็บๆ เพราะ AI อาจช่วยเขียน feature ได้ในเวลาอันสั้น ทว่าถ้าทีมยังต้องเสียเวลาขุดแชตเก่า ไล่อ่าน ticket เดิม และถาม System Analyst หรือ Senior Engineer ซ้ำๆ แล้วหละก็, productivity ที่เหมือนได้มาจาก AI ก็จะค่อยๆ หายไป จนสุดท้าย อาจจะทำงานได้เร็วกว่ากระบวนการเดิมเพียง 10-30% เท่านั้น (อ้างอิงจากหลายบทวิเคราะห์ เช่น arxiv.org, getdx.com, mckinsey.com – ฟิวส์)
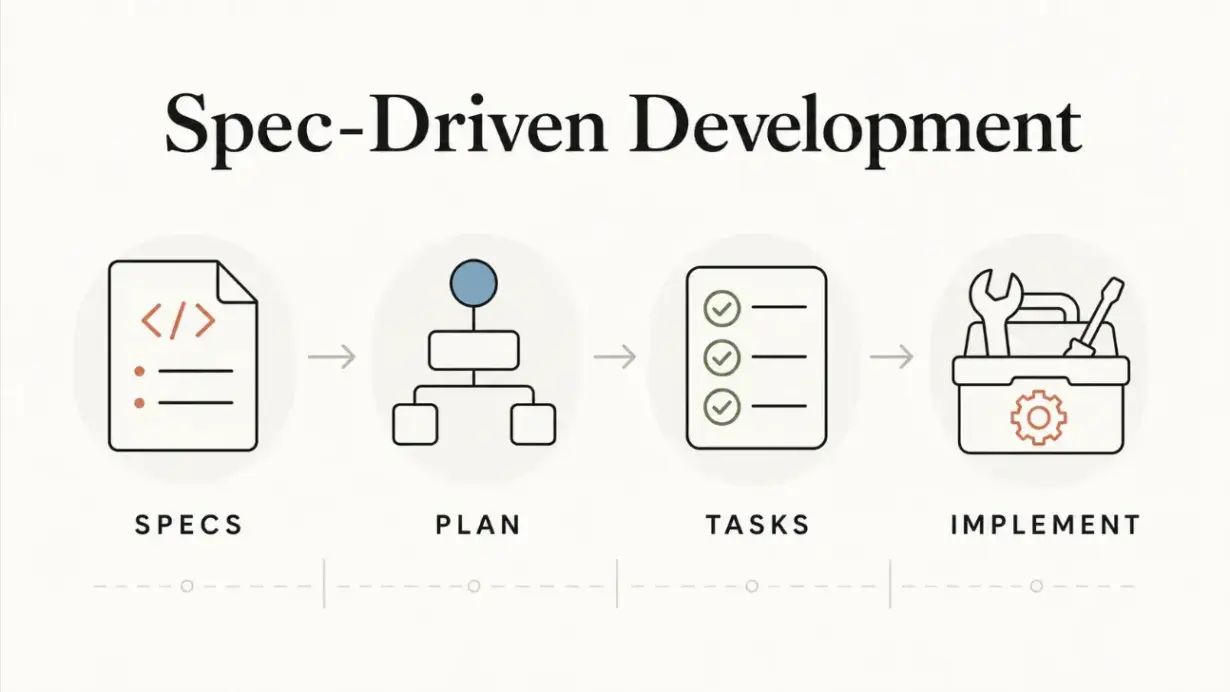
จาก Ticket และ PRD ที่เขียนครั้งเดียว ไปสู่ Living Spec
ข้อแนะนำของบทความนี้ คือ ให้ใช้ spec เป็นเอกสารกลาง และต้องยังอธิบายได้ว่า “ระบบควรทำอะไรในตอนนี้” ไม่ใช่เมื่อสามเดือนที่แล้ว หรือไม่ใช่ตอน kickoff โปรเจกต์ และไม่ใช่ตามความทรงจำของใครคนใดคนหนึ่ง.. (เจ็บปวดอีกแล้ว ฮ่าๆ)
ผู้เขียนได้แยกบทบาทของเอกสารได้คมมากๆ 3 ประเภท
| ประเภทเอกสาร (Artifact) | หน้าตาของเอกสาร | ช่วงเวลา |
|---|---|---|
| PRD (Product Requirement Document) | เอกสารส่งมอบอย่างเป็นทางการที่ระบุว่าผลิตภัณฑ์จะเป็นอย่างไร | Snapshot – เขียนเพียงครั้งเดียวในวันเริ่มต้นโครงการหรือกิจกรรม |
| Issues, Request, Jira Ticket (or Story Card) | ขอบเขตงานเล็กๆ ที่กำหนดไว้ซึ่งทีมกำลังดำเนินการในสปรินต์หรือกรอบช่วงเวลาหนึ่ง | Snapshot – จะฟรีช ณ ช่วงเวลาหนึ่งตามที่ PO/QA อนุมัติให้ทำ |
| Spec หรือ Living Document | คำอธิบายโดยละเอียดเกี่ยวกับสิ่งที่ผลิตภัณฑ์ทำได้ในปัจจุบันและสิ่งที่ควรจะทำได้ในอนาคต | Continuous – อัปเดตทุกครั้งที่ข้อกำหนดเปลี่ยนแปลง ที่ต้องสะท้อนความจริงปัจจุบันของพฤติกรรมระบบ |
นี่คือความต่างที่สำคัญมาก เพราะ PRD และ Ticket จะถูกฟลีชไว้และเก่าไปเรื่อยๆ ตามระยะเวลาที่พัฒนานานขึ้นเรื่อยๆ ผู้เขียนเรียกมันว่าเป็นหลักฐานของอดีต ในขณะที่ Spec ที่ดีควรเปลี่ยนตามความจริง ดังนั้นจุดแตกต่างของ Spec จึงไม่ใช่แค่การเปลี่ยนคำเรียกใหม่เท่านั้น แต่มันคือปรับวิธีการคิด และการต่อรองกันว่า ซอร์ฟแวร์เรากำลังไปในทิศทางไหน
อีกจุดที่ผู้เขียนเน้นชัด คือ Spec ไม่ควรกลายเป็น Technical Design Document หน้าที่ของมันคืออธิบาย What และ Why มากกว่า How ถ้าเอกสารเริ่มลงลึกถึง Endpoint, Database Schema หรือ Framework มากเกินไป เราก็กำลังเอาแปลนบ้านไปปนกับวิธีการก่ออิฐ เทปูน แล้ว (เป็นจุดที่ผมชอบใจการเปรียบเทียบมาก – ฟิวส์)
ตัวอย่าง เมื่อเทียบระหว่าง Spec (ในที่นี้คือ Product Spec) กับ Technical Spec
| Product Spec (อธิบายพฤติกรรม หรือเงื่อนไขทางธุรกิจ) | Technical spec / ADR (Solution) |
|---|---|
| “Manager must approve any invoice over $5,000″ | “Approval queue service with role-based routing” |
| “Submitter sees the approval status in real time” | “Push status updates via SSE / WebSocket” |
| “Approved invoices appear in the accounting system within 24 hours” | “Nightly batch sync to the accounting API” |
| “Submitter can attach a PDF receipt up to 25 MB” | “Pre-signed S3 upload; 25 MB enforced server-side” |
Spec ที่ดี ไม่ได้เขียนละเอียดหรือเยิ่นเย้อเกินไป แต่ต้องชัดเจน
ที่ผมชอบบทความนี้ คือ มันไม่ได้บอกแค่ว่า “ควรมี Spec” แต่ยังบอกด้วยว่า Spec ที่ใช้งานได้ควรมีอะไรบ้าง อย่างน้อยที่สุดควรตอบคำถามเหล่านี้ให้ได้
- ปัญหาที่กำลังแก้คืออะไร
- ใครคือผู้ใช้หรือผู้ได้รับผลกระทบ
- เป้าหมายคืออะไร
- อะไรคือสิ่งที่ตั้งใจไม่ทำ
- งานจะถือว่าเสร็จเมื่อไร
- มีข้อจำกัดอะไรที่ห้ามแตะ
- มีความเสี่ยงหรือคำถามอะไรที่ยังเปิดอยู่
ฟังดูเหมือนเรื่องพื้นฐาน แต่หลายทีมกลับไม่ค่อยเขียนส่วนที่สำคัญที่สุดอย่าง non-goals และ acceptance criteria ทั้งที่สองอย่างนี้คือรั้วกัน scope creep และเป็นภาษากลางที่ช่วยให้ PM, Dev, QA และ AI มองโจทย์เดียวกันด้วยสายตาใกล้เคียงกันมากขึ้น
พูดให้ง่ายขึ้น Spec ที่ดีไม่ใช่เอกสารที่เยอะ แต่เป็นเอกสารที่ทำให้การเดาลดลง คนอ่านแล้วไม่ต้องตีความเอาเองเยอะ และ AI อ่านแล้วไม่เผลอเลี้ยวเข้าเส้นทางที่ไม่มีใครตั้งใจให้ไป
ลองดูตัวอย่างโครงสร้างของ Spec (ซึ่งถ้าใครเคยสังเกต Spec ที่ AI เขียน ก็จะมีหัวข้อพื้นฐานประมาณนี้แหละ – ฟิวส์)
# [Feature Name]
**Status:** Draft | In Review | Approved | Superseded
**Owner:** [Name / Team]
**Last Updated:** [YYYY-MM-DD]
## Problem
A specific story showing why the status quo doesn't work. Name the user.
## Users
| User | Role | Context |
| -------------- | -------------- | -------------------- |
| [Name/Persona] | [What they do] | [Relevant details] |
## Goals
- [Outcome this feature serves]
## Non-Goals
- [Thing we are deliberately not doing — prevents scope creep]
## Acceptance Criteria
- **AC-1:** [Concrete, testable, plain-language behavior]
- **AC-2:** ...
## Constraints
| Constraint | Source | Impact |
## Risks & Open Questions
- [ ] [Decision still to be resolved]เหตุผลที่ AI ชอบเอกสารชัดๆ มากกว่าความคลุมเครือ
หนึ่งในประโยคที่คมที่สุดของบทความนี้คือ AI works from the spec, not from assumptions.
ถ้าเราส่งงานให้ AI โดยข้อมูลยังแยกกันอยู่ใน Slack, Jira, meeting transcript หรือจากความทรงจำของใครสักคนในทีม AI โมเดลก็จะต้องเติมช่องว่างเองด้วยการเดา และหลายครั้งสิ่งที่เราบ่นว่าเป็น AI Hallucination หรือ อาการหลอนของ AI ก็อาจเป็นเพาะเราเอง ที่ป้อนข้อมูลให้แบบขาดๆ เกินๆ (โทษตัวเองบ้างนะ ฮ่าๆ)
แต่ถ้าทีมมี Spec ที่ดี AI จะเห็นภาพรวมในที่เดียว มันรู้ว่าเป้าหมายคืออะไร อะไรเป็น non-goal อะไรห้ามเปลี่ยน และอะไรคือเกณฑ์ที่จะใช้ตัดสินว่างานเสร็จจริงหรือยังไม่เรียบร้อย แบบนี้ขอบเขตของความผิดพลาดจะลดลงเยอะมาก จากเดิมที่ให้ผลลัพธ์มั่วได้ตั้งแต่การตีความต้องการของเราผิด ก็จะเหลือเพียงปัญหาเชิง implementation ที่เราสามารถใช้กระบวนการ test และ review แก้ไขตามหลังได้
นี่คือเหตุผลที่ผู้เขียนย้ำกฎเหล็กไว้ชัดมากว่า ต้องอัปเดต Spec ก่อนเขียนโค้ดเสมอ เพราะถ้า AI ทำงานต่อไม่ได้ สิ่งที่ควรทำไม่ใช่ฝืน prompt ใหม่ไปเรื่อยๆ แต่ต้องย้อนกลับมาแก้ความไม่ชัดเจนที่ต้นทางก่อน
ถ้าอยากเริ่มใช้จริง ไม่จำเป็นต้องปฏิวัติทั้งองค์กรในวันเดียว
แนวคิดนี้สามารถเริ่มได้ไม่ยาก และเริ่มเล็กๆ ได้ ผู้เขียนแนะนำให้เริ่มจาก feature เดียวที่เจอความสับสนซ้ำๆ เช่น workflow อนุมัติเอกสาร การสร้างรายงาน การแจ้งเตือน หรือ onboarding flow แล้วเขียน spec ให้ชัดสำหรับเรื่องนั้นเรื่องเดียวก่อน
จากนั้นค่อยกำหนด Standard ให้ทีมเขียน Spec เช่น
- เขียน goals และ non-goals ให้ครบ
- ใช้ acceptance criteria เป็น definition of done ร่วมกัน
- แยก spec ออกจาก technical design ให้ชัด
- เมื่อ requirement เปลี่ยน ให้แก้ spec ก่อนเสมอ
- ถ้ายังต้องใช้ Jira อยู่ ก็ใช้ต่อได้ แต่ให้มันทำหน้าที่ระบบติดตามงาน ไม่ใช่ที่เก็บความจริงสูงสุดของระบบ (ระวังจะ Outdate)
อีกเรื่องที่น่าสนใจคือวิธีวัดผล อย่าวัดแค่ว่า AI เขียนโค้ดเร็วขึ้นกี่เปอร์เซ็นต์ ลองวัดว่า สามารถขึ้นงานได้เร็วขึ้นไหม, จำนวนคำถามย้อนกลับลดลงไหม, QA กับ Dev เข้าใจตรงกันมากขึ้นไหม และเวลา review ใช้กับการแก้ความเข้าใจผิดน้อยลงหรือเปล่า ตัวชี้วัดพวกนี้อาจบอกความคุ้มค่าของ Spec ได้ชัดกว่าตัวเลขเรื่องความเร็วล้วนๆ
ผมรู้สึกอย่างไรกับบทความนี้
สิ่งที่ผมชอบที่สุดในบทความนี้คือมันไม่ได้พยายามขายฝันว่า AI จะมาแทนทุกอย่างพรุ่งนี้เช้า แต่ค่อยๆ ชี้ให้เห็นว่า เมื่อเครื่องมือเร็วขึ้น ความเข้าใจและความต้องการของมนุษย์ยิ่งต้องชัดขึ้นด้วย ถ้าเมื่อก่อนเราแพ้เพราะเขียนโค้ดช้า วันนี้เราอาจแพ้เพราะคิดไม่ชัดแทน
Spec-Driven Development จึงไม่ใช่แฟชั่นในการทำเอกสาร หรือการกำหนดรูปแบบเอกสารใหม่ แต่มันคือความพยายามจะเก็บ “ความหมายของระบบ” ไว้ในที่ที่ทั้งคนและเครื่องเข้าไปหยิบใช้ได้และเข้าใจตรงกัน
อ้างอิง
- Evgeni Rusev, Spec-Driven Development: A Practical Guide for AI-Accelerated Teams
https://evgenirusev.com/posts/spec-driven-development-guide/


